
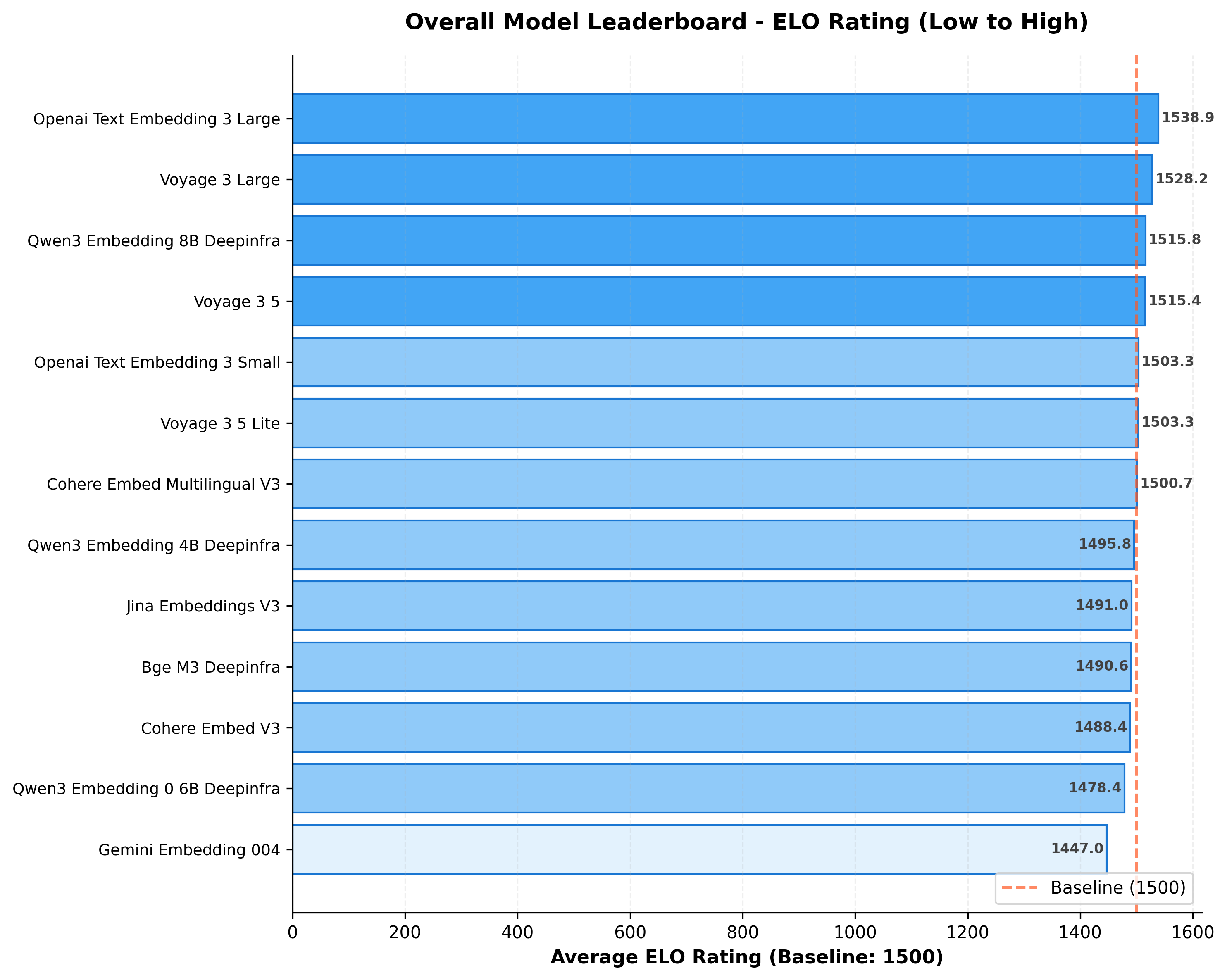
We compared 13 embedding models across 8 datasets using an LLM judge and ELO scoring. Results showed that most of the models land within 50 ELO points, clustering tightly around baseline performance.
Key numbers
- 7 of 13 models sit at or above the 1500 baseline
- 11 of 13 are within 50 ELO points
- Only 2 models clearly underperform (Qwen3-0.6B, Gemini-004)
- Rank 1 → rank 10 difference is around 3%
Basically, the winners aren’t winning much.
Why this matters
The embedding landscape is crowded now – OpenAI, Cohere, Google, Voyage, Qwen, Jina, BAAI. Every model comes with claims of higher scores and better benchmarks, and it is easy to think this choice is critical. But when you test the models in a setup that feels closer to actual retrieval, the differences get very small.
What we found
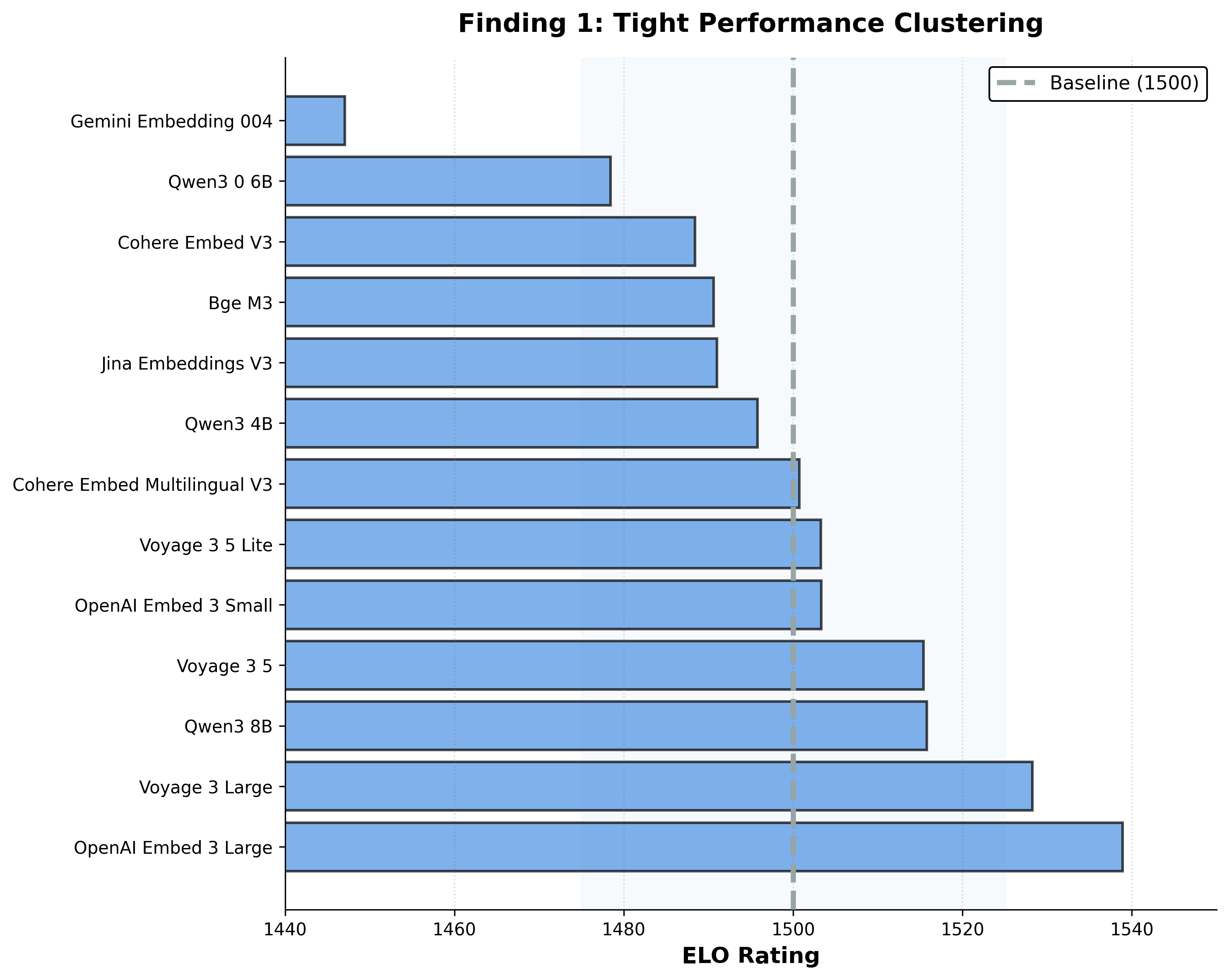
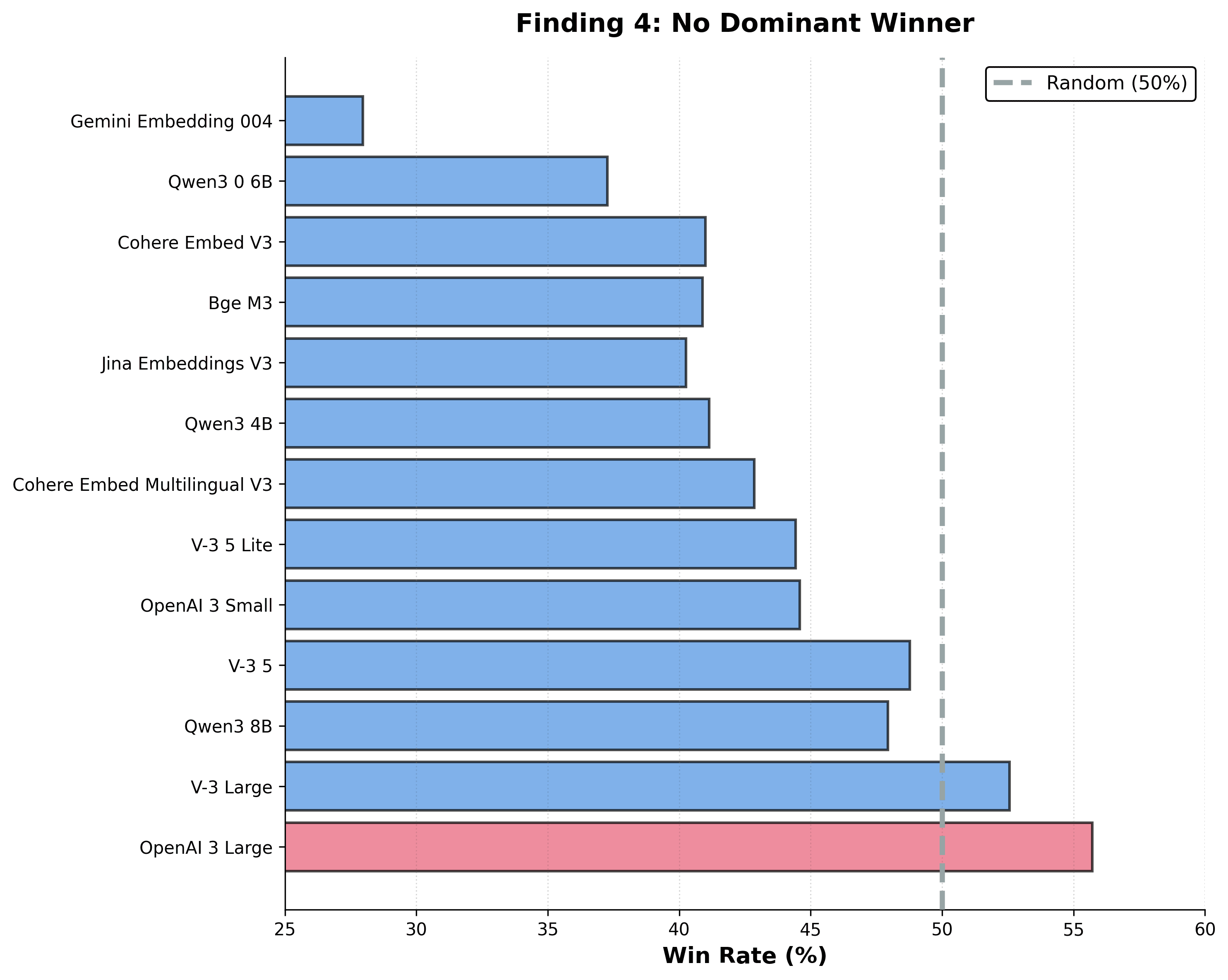
- Tight clustering — 85% of models sit inside the same 50-point ELO band.
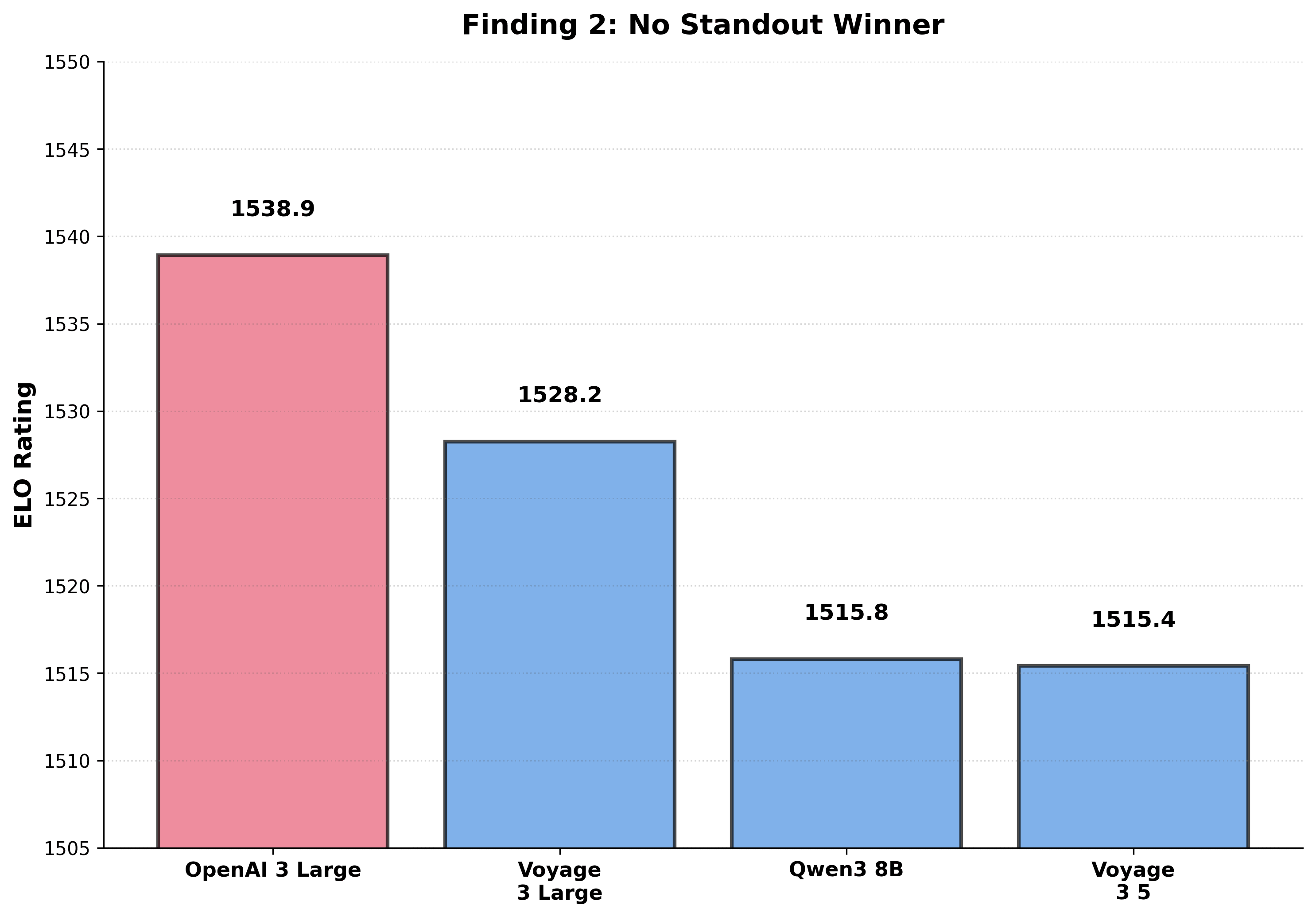
- No standout model — the top 4 are only about 23.5 ELO points apart.
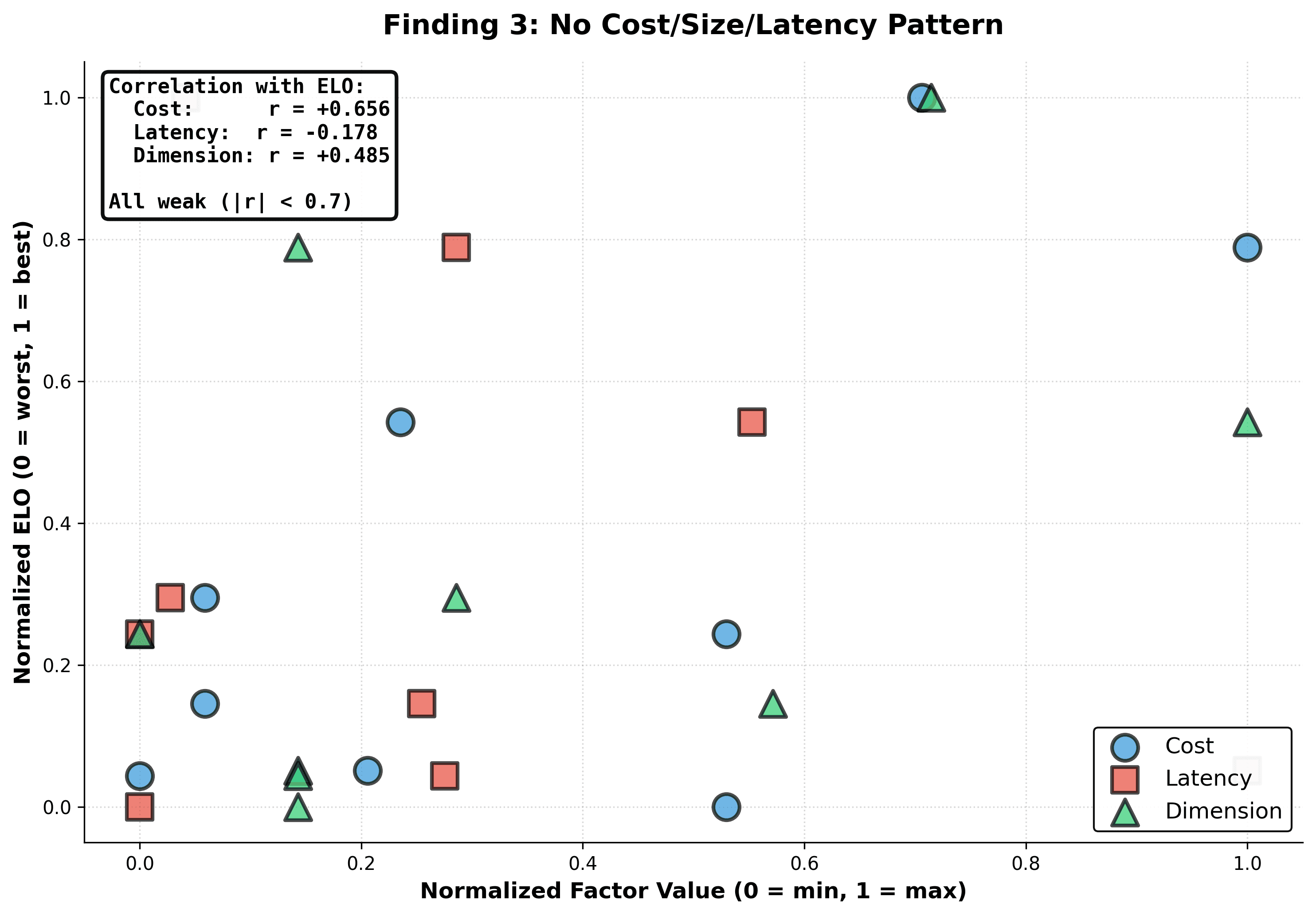
- No cost, size, or latency pattern — price or scale does not predict quality.
- No dominant winner — even the top model wins only around 56% of matchups.
Overall, modern embedding models are clustered so closely that most of them behave almost the same.
But why do they all perform the same?
Embedding models all aim to solve a fairly limited task: mapping meaning into a vector space. Since most providers use similar data, similar architectures, and train toward the same kind of goal, improvements get small very quickly. After that point, the models naturally settle into the same performance range.
How we tested
- 13 models (OpenAI, Cohere, Voyage, Qwen, Jina, BGE, Gemini)
- 8 datasets across essays, financial QA, business docs, and multilingual QA
- Two models retrieve for the same query
- ChatGPT 5 picks which result list is better
- ELO converts thousands of pairwise decisions into a single score per model
Conclusion
Embedding models have largely converged. Other than the smallest or deprecated models, everything else performs very similarly, and most models fall into the same tight band.
Overall, choosing the right model seems to come down to cost, speed, and deployment, while the real gains in RAG come from chunking, hybrid search, and reranking.
You can see the full breakdown and model rankings on the embedding leaderboard.