
Gemini 3 was released yesterday, we wanted to see how it behaves inside a real RAG pipeline, not just in isolated prompt tests.
We used the same retrieval, same context, and the same evaluation flow to compare it directly with GPT 5.1.
We looked at five areas that matter for RAG: conciseness, grounding, relevance, completeness, and source usage.
Conciseness
We started by looking at conciseness: can the models ignore the noise and stick to the essential answer?
GPT 5.1: Answered the “boil eggs” question with only the essential steps, giving a short and clean method.
Gemini 3: Pulled in everything from the retrieved chunk — sous-vide, temperature variants, extra techniques — making the answer far longer than needed.

Citations & grounding
What about when you ask something the model doesn’t know?
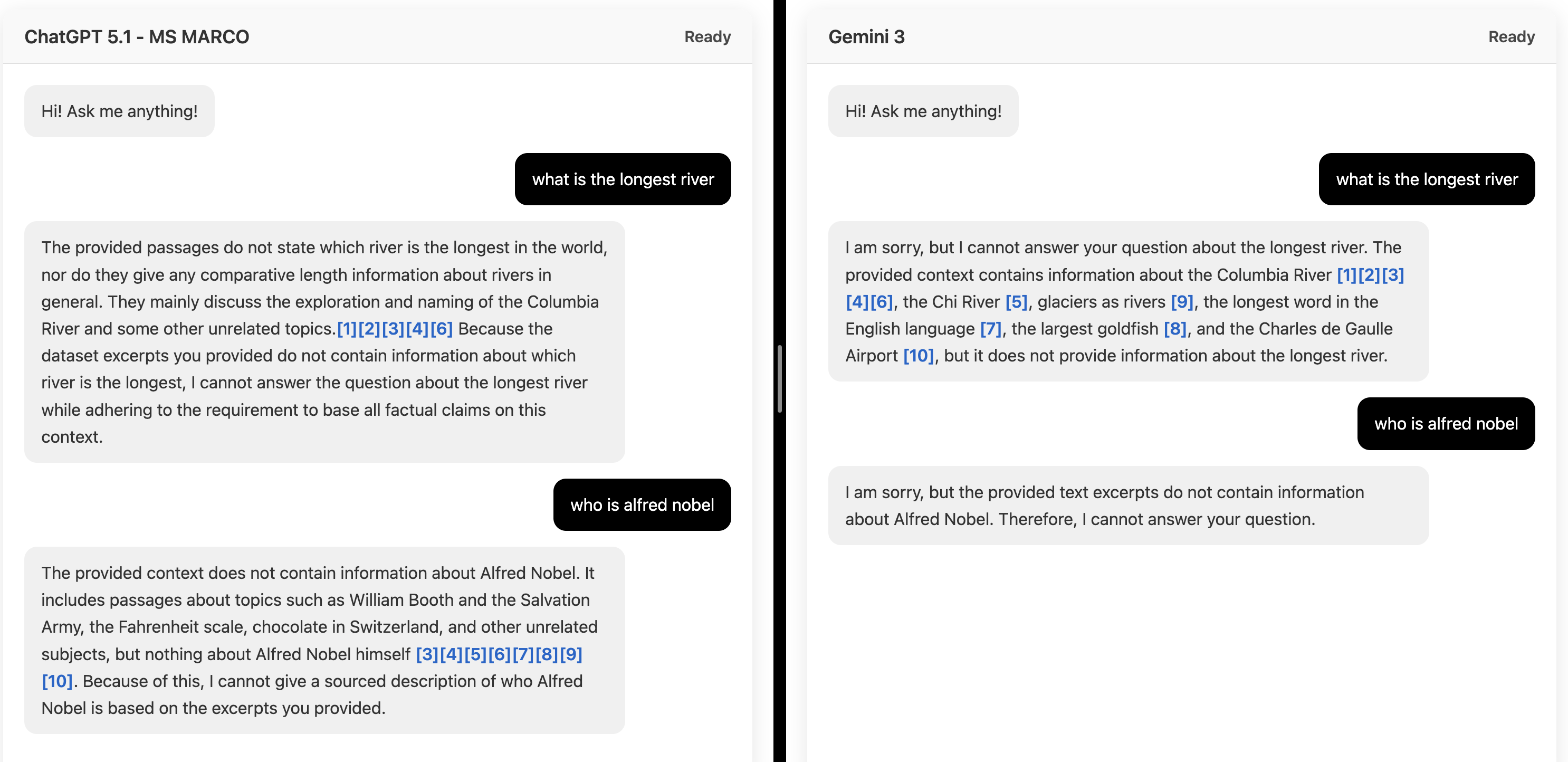
In our tests, both models refused to answer questions they couldn’t ground in the context, which is what you want. But when the context was messy, they added extra details in different ways:
GPT 5.1: Over-explained its refusal by citing every unrelated name or topic mentioned.
Gemini 3: Pulled in random facts it saw inside the retrieved chunks.
Relevance
In this example as well, when asked about symptoms of dehydration,
GPT 5.1: Pulled in a long list of unrelated medical symptoms, drifting away from the relevant retrieved content.
Gemini 3: Stayed closer to the retrieved text and ignored irrelevant symptoms.

Completeness / reasoning
When it comes to explaining a process or definition, both models answered the question, but neither stayed tightly focused.
GPT 5.1: Included every line that mentioned any analyst keyword, adding responsibilities that were not relevant to AML.
Gemini 3: Listed the main duties from the retrieved text without adding irrelevant roles.

Source usage
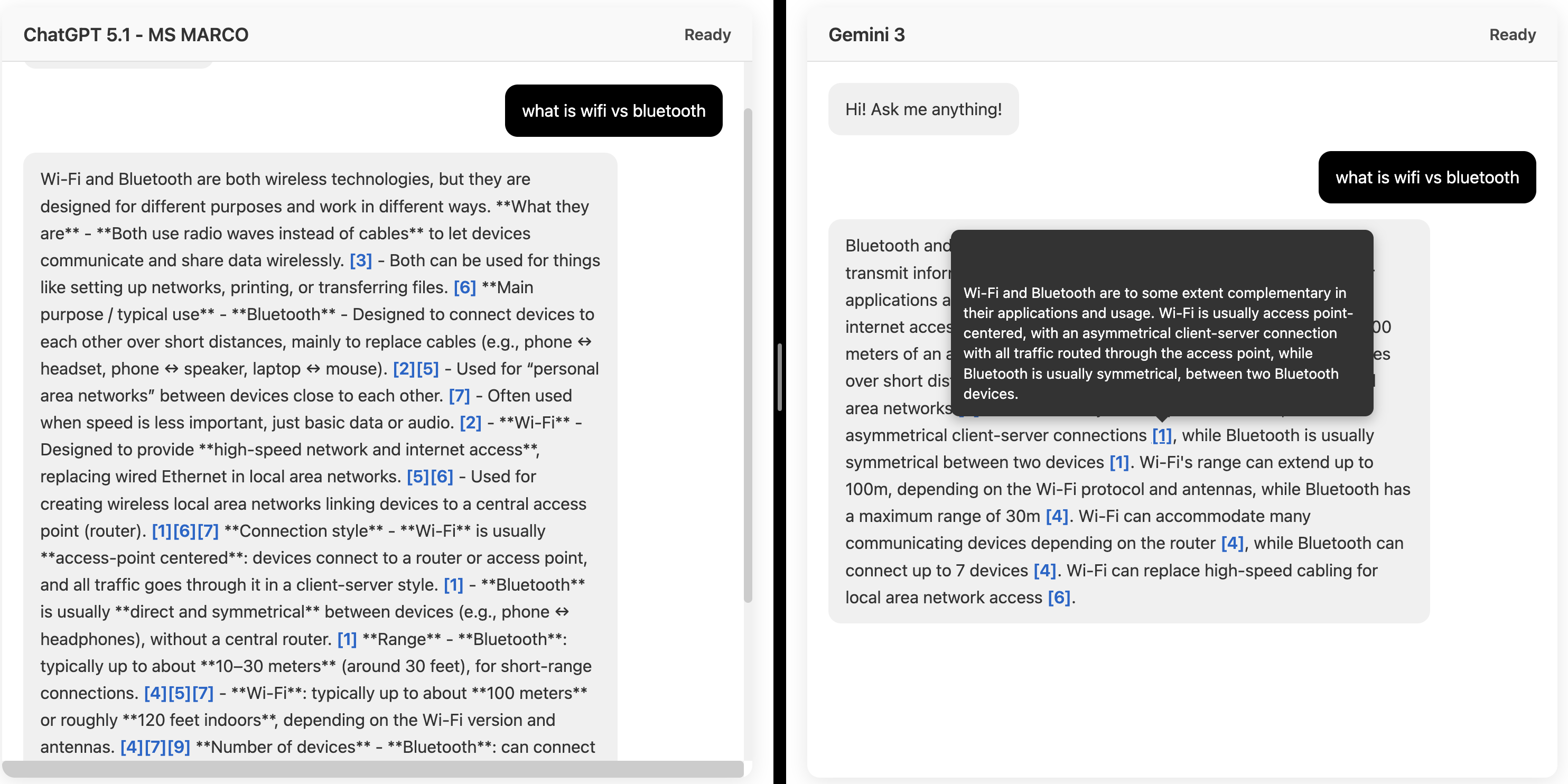
How well do they use sources for each query?
GPT 5.1: Added a lot of extra details, dumping everything it found about WiFi and Bluetooth.
Gemini 3: Organized the retrieved text better and kept the comparison concise and focused. As you see, it also answers using the correct chunks.
What can we say about each model with these comparisons?
| Category | Gemini 3 | GPT-5.1 | Verdict |
|---|---|---|---|
| Conciseness | Much longer; includes every detail it finds. | Shorter, sticks to core steps. Avoids extra methods. | GPT-5.1 |
| Citations & Grounding | Refuses cleanly but also over-cites. | Refuses but over-cites unrelated names/topics. | Both are same |
| Relevance | Stays on-topic; ignores irrelevant symptoms. | Drifts by including unrelated medical details. | Gemini 3 |
| Completeness / Reasoning | Covers the core duties without adding irrelevant roles. | Adds unrelated analyst responsibilities; more noise. | Gemini 3 |
| Source Usage | Organizes retrieved text into a concise answer. | Dumps all details from the context; heavy output. | Gemini 3 |
In 3/5 cases, Gemini 3 stays closer to the retrieved text, keeps answers focused, and avoids drifting.
ChatGPT 5.1 is more expressive but also more prone to pulling in extra unnecessary details.
This shows that each model leans toward a different style, so maybe the right choice depends on the type of answers you value.