
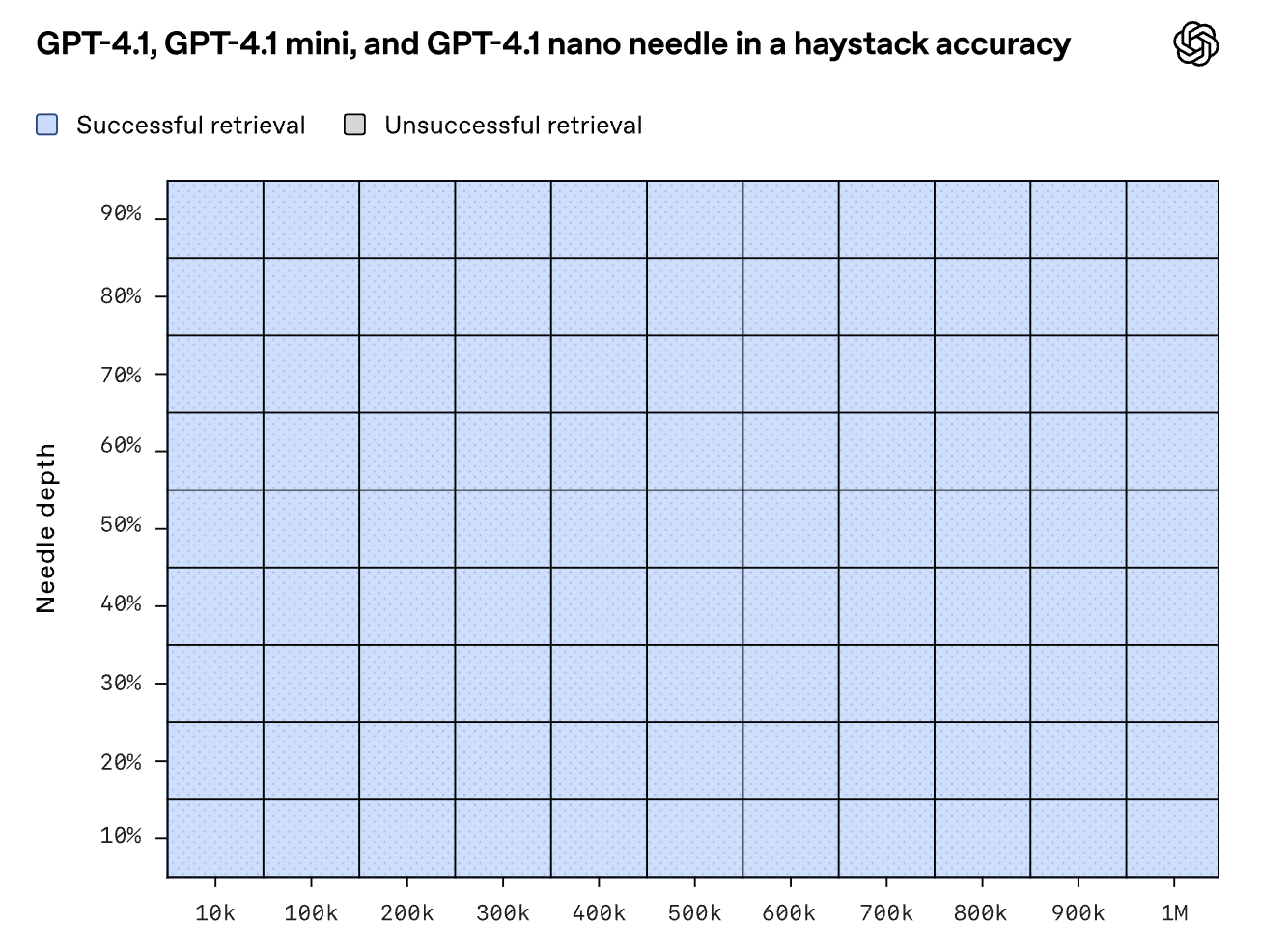
OpenAI announced the GPT 4.1 family of models yesterday, with a 1M-token context window and perfect needle-in-a-haystack accuracy. Gemini 2.5 supports a 1M-token context window, and a 10M-token context window in research.
As the founder of a RAG-as-a-service startup, I now commonly receive messages after new model announcements, saying that RAG is dead and that we should pivot to a different problem.
In this article, I’ll walk you through why we’re betting on RAG and why we don’t think it’s going away any time soon.
The promise of large context windows
Large context windows, at first glance, look appealing. They promise:
- Working with large amounts of information
- The simplicity of using an LLM provider’s API directly
- Not missing results that are present in the context
Anyone who tried using large contexts in production knows how this turns out, but let me break it down.
Cost and Speed
A typical RAG request takes about 1K tokens; passing 1M tokens multiplies the cost by 1000x ($0.002 → $2) per query, and increases latency by a less substantial factor. In OpenAI’s demo yesterday, a 456K token request took 76 seconds. In fact, the team thought that the demo wasn’t working for a moment.
Agentic Workflows
Why are cost and speed important? It’s because AI workflows are becoming agentic, requiring multiple LLM calls and steps before reaching the final result. The cost and speed implications multiply, and it becomes cost-prohibitive and virtually unusable for large applications.
Citations
LLM architectures don’t natively support citations, i.e., giving references to the original text and allowing users to navigate to the original source. In RAG, this is done by referencing the chunk from which the information came. Here's an example of how Perplexity does citations:

Context Size
1M tokens is quite substantive (~20 books), but it’s not big enough for use cases that have a non-trivial amount of data. One of the companies we work with has 6.1B (B for a billion) tokens worth of content. A 10M or even a 100M context window will not be enough to incorporate all their content. Nor will tokenomics work at that scale.
So, is RAG Dead?
RAG is still the only viable way for companies to work with non-trivial amounts of data. Given the rate of AI improvements, we wouldn’t be surprised if there are architectural breakthroughs in the next couple of years that would make context-window-only approaches viable. But until then, we’re betting on RAG.