

Modern RAG systems depend on two pillars:
- high-quality embeddings
- fast, accurate vector retrieval
The vector database handles the second part: storing embeddings and returning the closest matches to a query. Retrieval quality in practice depends on chunking, embeddings, and how you query. The vector database mostly controls how fast and how reliably that search works as your data grows.
There are now dozens of vector databases, all promising speed, accuracy, and “production-grade” performance. We looked at seven of them and asked a simple question: how do they differ, and which ones make sense for different RAG setups?
This post is a short overview of what we found.
Context
A vector database stores embeddings and returns the closest matches to a query. In RAG, it decides which pieces of text the model sees first, which indirectly affects grounding, hallucination, and answer quality.
To compare systems, we looked at three things:
- how they are deployed
- how they are priced
- what they seem to be optimised for
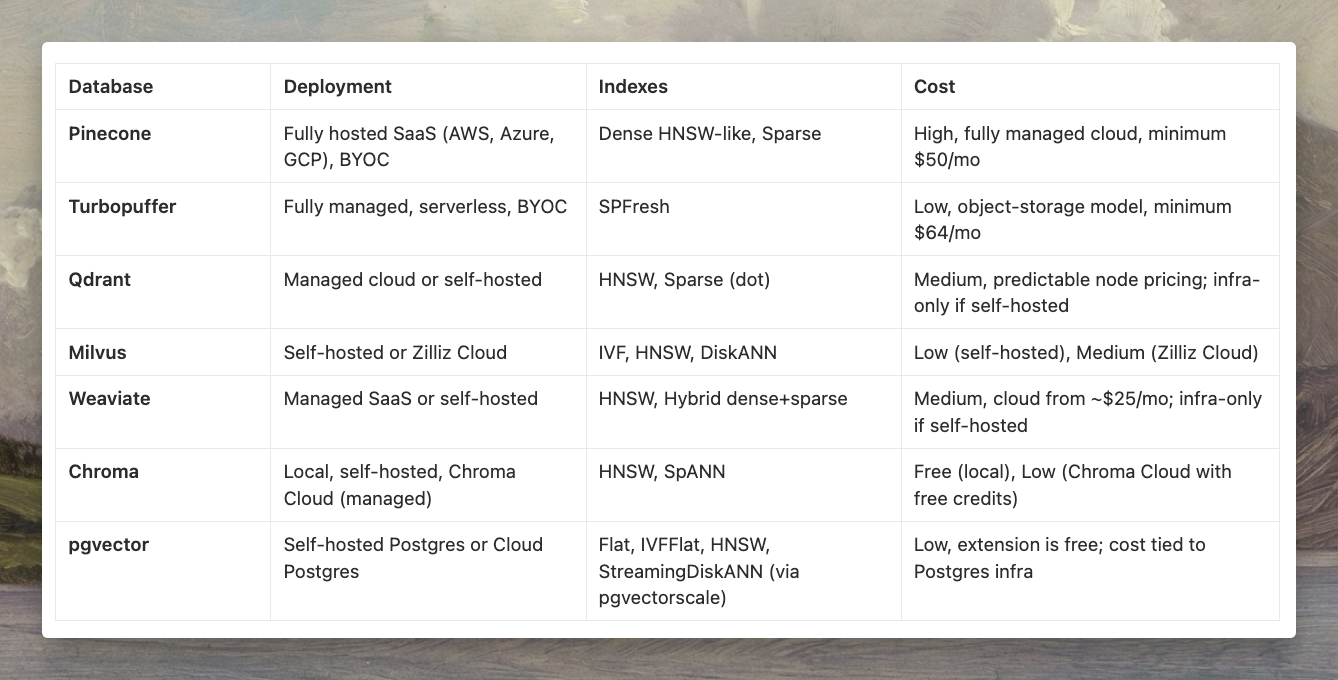
We focused on seven options: Pinecone, Turbopuffer, Qdrant, Milvus, Weaviate, pgvector, and Chroma.
What We Found
Deployment is the first decision
The comparison above shows a clear pattern: deployment model is usually the first real choice.
- Pinecone and Turbopuffer have managed APIs. You call an endpoint; they run the cluster.
- Qdrant, Milvus, and Weaviate are open-source databases you can self-host or consume via their clouds.
- pgvector lives inside Postgres; Chroma usually runs inside your app or as a small local service.
So the first split is simple: separate managed service, self-hosted vector database, or something embedded in what you already run.
Indexing differences matter at scale
All seven support HNSW or similar approximate nearest neighbour indexes. On top of that:
- Turbopuffer's SPFresh is built around object storage economics
- Milvus adds DiskANN for larger-than-memory indexes
- Weaviate offers hybrid dense + sparse search in a single query
- pgvectorscale brings StreamingDiskANN-style behaviour into Postgres
For most RAG systems under roughly 10M vectors, a standard HNSW setup is usually enough. Above that, index choice and layout start to matter more.
Cost follows deployment, then scale
- lowest cost: self-hosted pgvector, local Chroma, or self-hosted Qdrant/Milvus (you mainly pay infra)
- medium cost: managed Qdrant Cloud, Weaviate Cloud, or Turbopuffer at moderate scale
- highest cost: Pinecone, but you are paying to have the whole vector layer managed for you
The point where Turbopuffer becomes cheaper than Pinecone depends on data size and query patterns, but the shape is clear: as your stored vectors grow, object-storage designs become more attractive.
Best Use-Cases
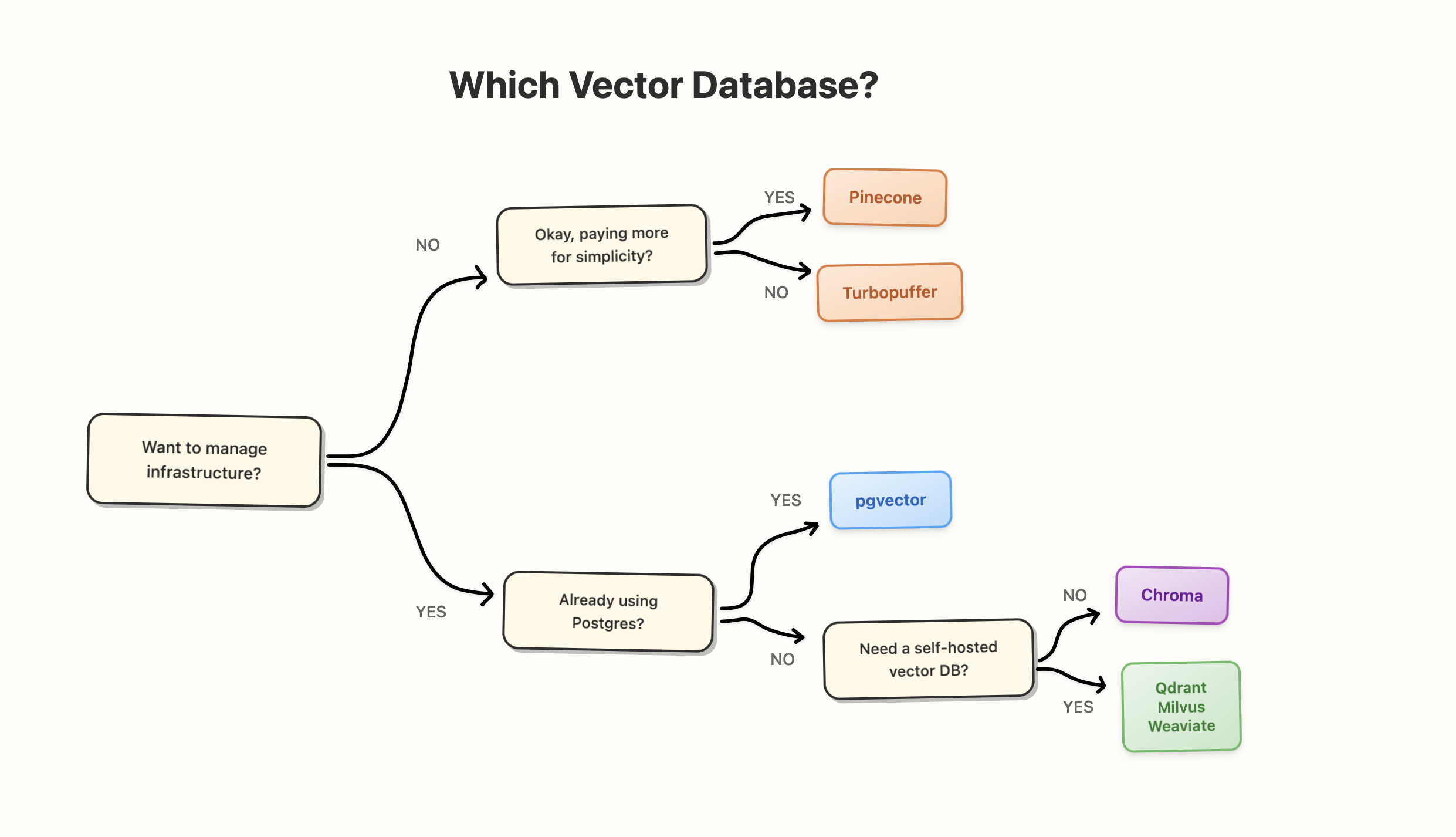
1. Need production RAG without running infrastructure?
Pinecone is the natural choice here: managed, predictable, and built specifically for this use-case.
For very large and cost-sensitive setups, Turbopuffer becomes interesting because of its object-storage design and focus on cheap large-scale storage.
2. Need open-source and more control?
Qdrant is a solid first pick when you want open-source and flexibility. You can run it yourself or use Qdrant Cloud if you prefer not to manage everything.
For larger deployments with more index options and tuning, Milvus is another strong candidate. Weaviate fits best when you care about hybrid search (semantic + keyword) and richer schema.
3. Already live in Postgres or small local services?
pgvector (and pgvectorscale at higher scale) fits Postgres-centric stacks where you want vectors and relational data in the same place and prefer to keep everything inside that database.
Chroma fits local experiments, notebooks, and smaller RAG services where a simple process or small server is enough and you don't want a separate vector cluster at all.
Our pick
Across these seven, Pinecone is the strongest default for managed, production RAG.
It is fully managed, focuses on predictable latency, and hides most of the operational details. For many teams, that trade-off is worth more than extra control.
Two others stand out clearly:
- Turbopuffer for very large datasets where storage cost is a primary concern
- Qdrant when you want an open-source database you can run yourself, with a cloud option if you don't
pgvector and Chroma sit in a different niche:
- pgvector when your stack already runs on Postgres and you prefer to keep vectors and relational data together
- Chroma when you want a light-weight local or small-server setup instead of a separate vector service
Closing
Taken together, the picture is simple: each database naturally falls into a role.
- Pinecone is the clearest default for managed, production RAG
- Turbopuffer stands out for large, cost-sensitive workloads
- Qdrant is a strong open-source option, with Milvus and Weaviate close by for larger or more specialised setups
- pgvector and Chroma make sense when adding a separate vector service doesn't feel justified yet
If you want full metrics, index details, and side-by-side breakdowns, you can find them on our vector database leaderboard.