

Gemini 3 Flash Preview just dropped, so we tested it in a RAG setup to see where it’s actually strong (and where it isn’t).
TL;DR
- Solid overall: ranks #3 in our run (ELO ~1607)
- Best at straightforward factual QA: ~68% win rate (+28pp vs its average)
- Less reliable on science / reasoning: closer to a coin flip (~51%), often “safe but shallow”
- Very grounded: top-tier relevance and faithfulness, but answers can be less complete
Key findings
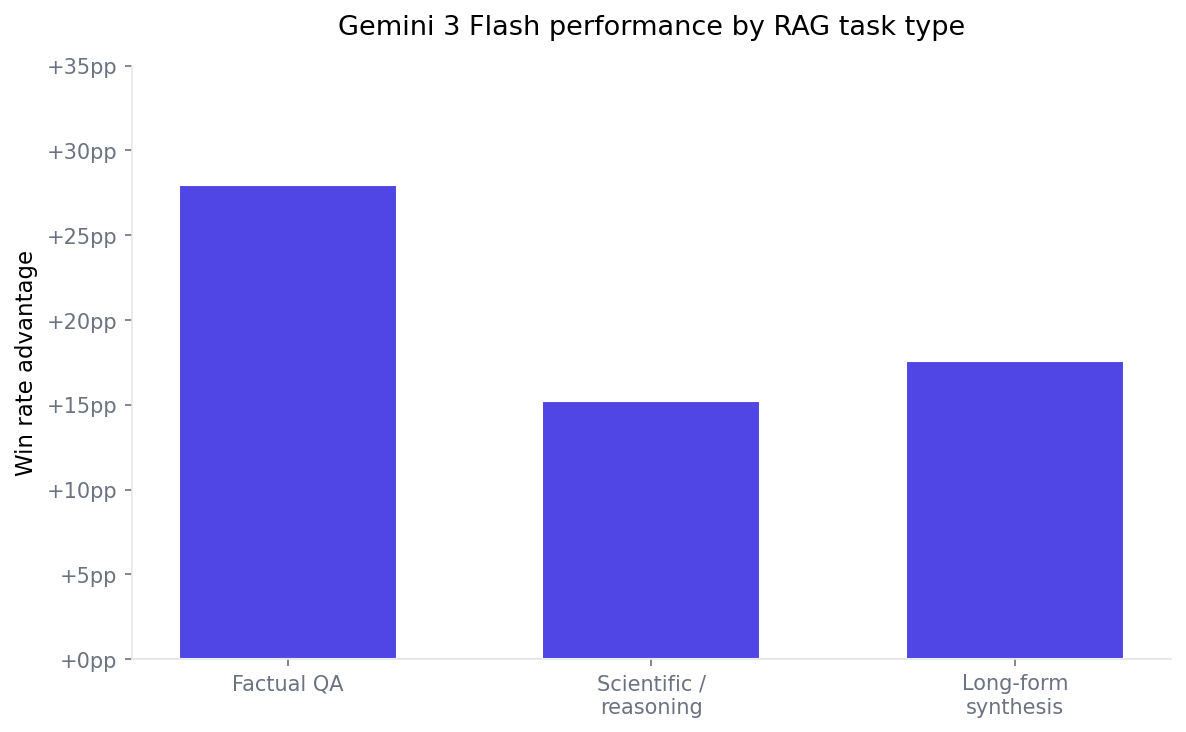
Factual retrieval is the sweet spot
On straightforward factual QA, Gemini 3 Flash shows its strongest results. It achieves a ~68% win rate, which is ~28 percentage points above its average performance across task types — nearly 2× higher than its advantage on reasoning-heavy workloads.
This isn’t just a small bump. In relative terms, factual QA is where Flash separates itself most clearly from its own baseline. It ranks #3 out of 11 models on this task type, outperforming most alternatives, including Gemini 2.5 Pro and Gemini 3 Pro.
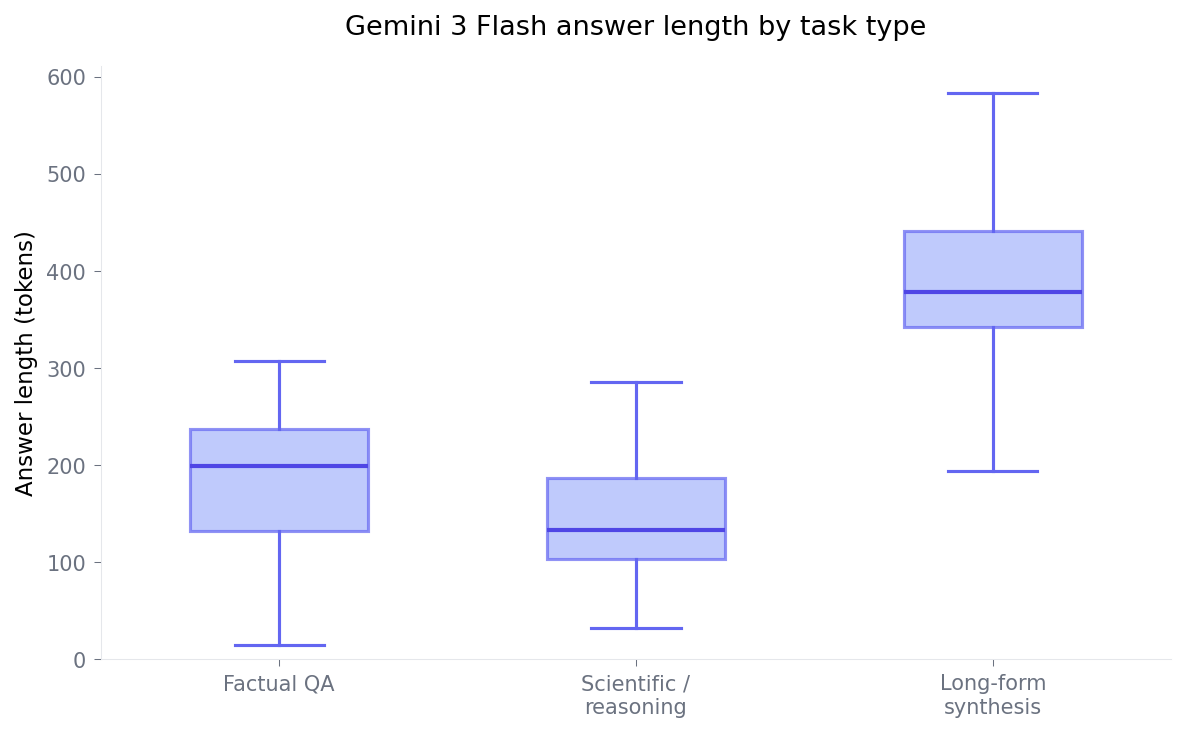
Depth is the limitation
Once tasks move beyond extraction into claim verification or multi-step reasoning, Flash becomes noticeably more conservative. Performance drops to around ~51% win rate, which is close to a coin flip.
The answer-length plot helps explain the behavior: Flash can produce long outputs (it does on long-form synthesis), but on reasoning-heavy tasks its responses stay relatively short. That’s often the “correct but not fully worked through” pattern — it doesn’t expand into deeper synthesis when the task benefits from it.
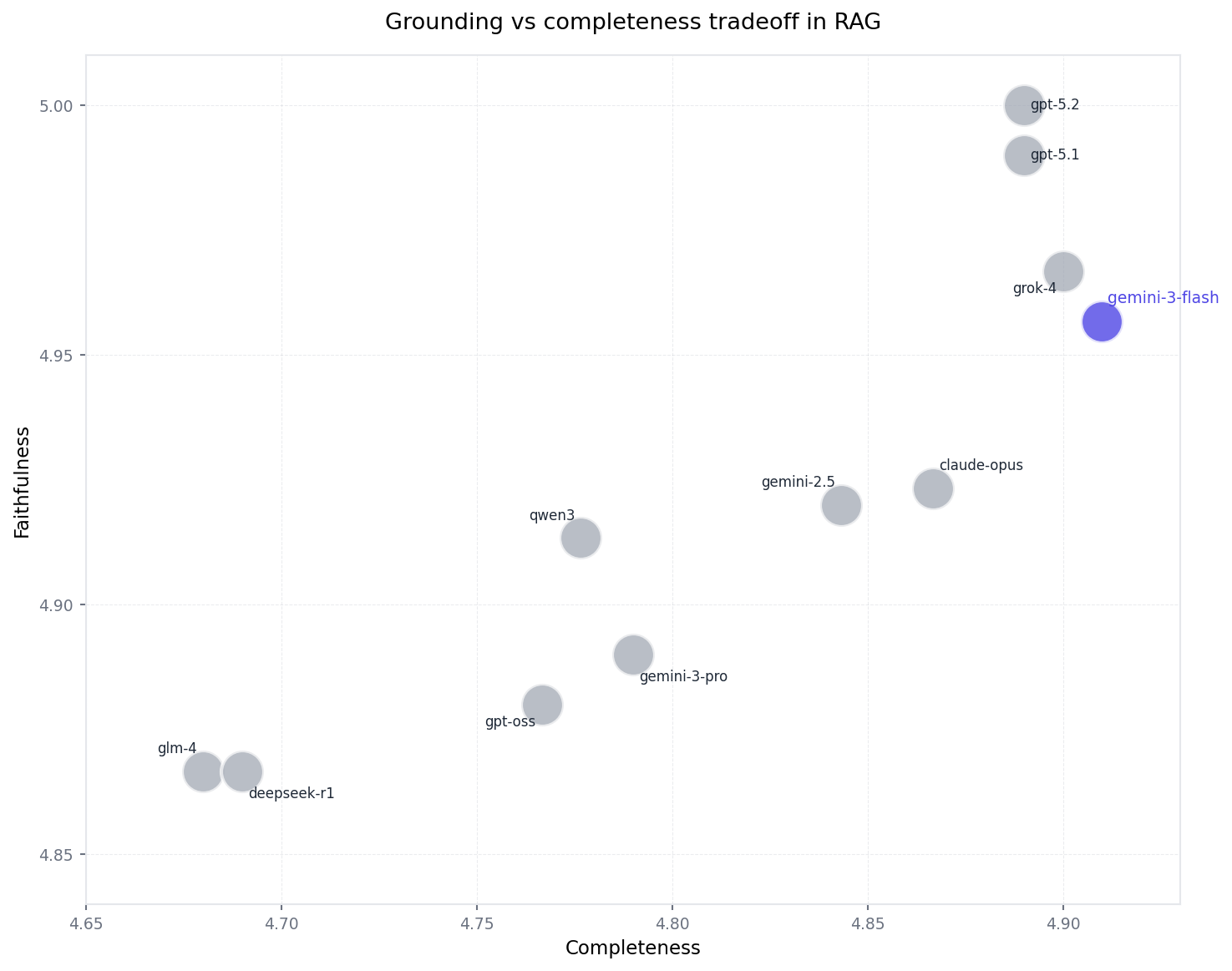
Grounding over completeness (the core tradeoff)
Flash’s strongest trait is grounding. On the grounding plot, it sits near the top on faithfulness (~4.96–4.98), meaning it sticks to the retrieved context and rarely hallucinates or drifts.
The tradeoff is completeness. Even when the answer is correct, Flash often stops once it’s delivered the minimum supported response. That’s why it can feel thinner than deeper models on nuanced questions — not because it’s making things up, but because it’s choosing safety over expansiveness.
Conclusion
Gemini 3 Flash is a strong choice for fast, factual, low-hallucination RAG — especially for support, FAQ, and internal search use cases. For science-heavy or reasoning-heavy queries, deeper models still perform better due to stronger synthesis and more complete answers.
We’ve added Gemini 3 Flash Preview to the Agentset LLM leaderboard so you can compare it against GPT-5.x, Grok, Claude, Gemini Pro, and more across tasks.