
We plugged GPT-5.2 into the same RAG benchmark we use for our LLM leaderboard and compared it against 9 other frontier models, including GPT-5.1, Claude Opus 4.5, Grok-4-Fast, Gemini 3 Pro, and the strongest open-source options.
All models went through the exact same RAG stack across three workloads:
- short factual Q&A
- long-form reasoning and synthesis
- scientific claim verification
In this setup, GPT-5.2 lands in the top cluster, but behaves differently from GPT-5.1 and the other leaders. It writes much shorter answers, uses far fewer tokens, and is especially strong when it has to read evidence and decide whether a claim holds.
How We Tested
Same setup as in our main RAG benchmark:
- Retrieval: text-embedding-3-large + zerank-1, top-15 documents.
- Generation: 10 frontier LLMs answering the same questions with the same retrieved context.
- Judging: GPT-5, comparing answers in pairs.
- Scoring: pairwise wins → ELO; plus per-answer scores on correctness, faithfulness, grounding, relevance, and completeness.
What We Found About GPT-5.2
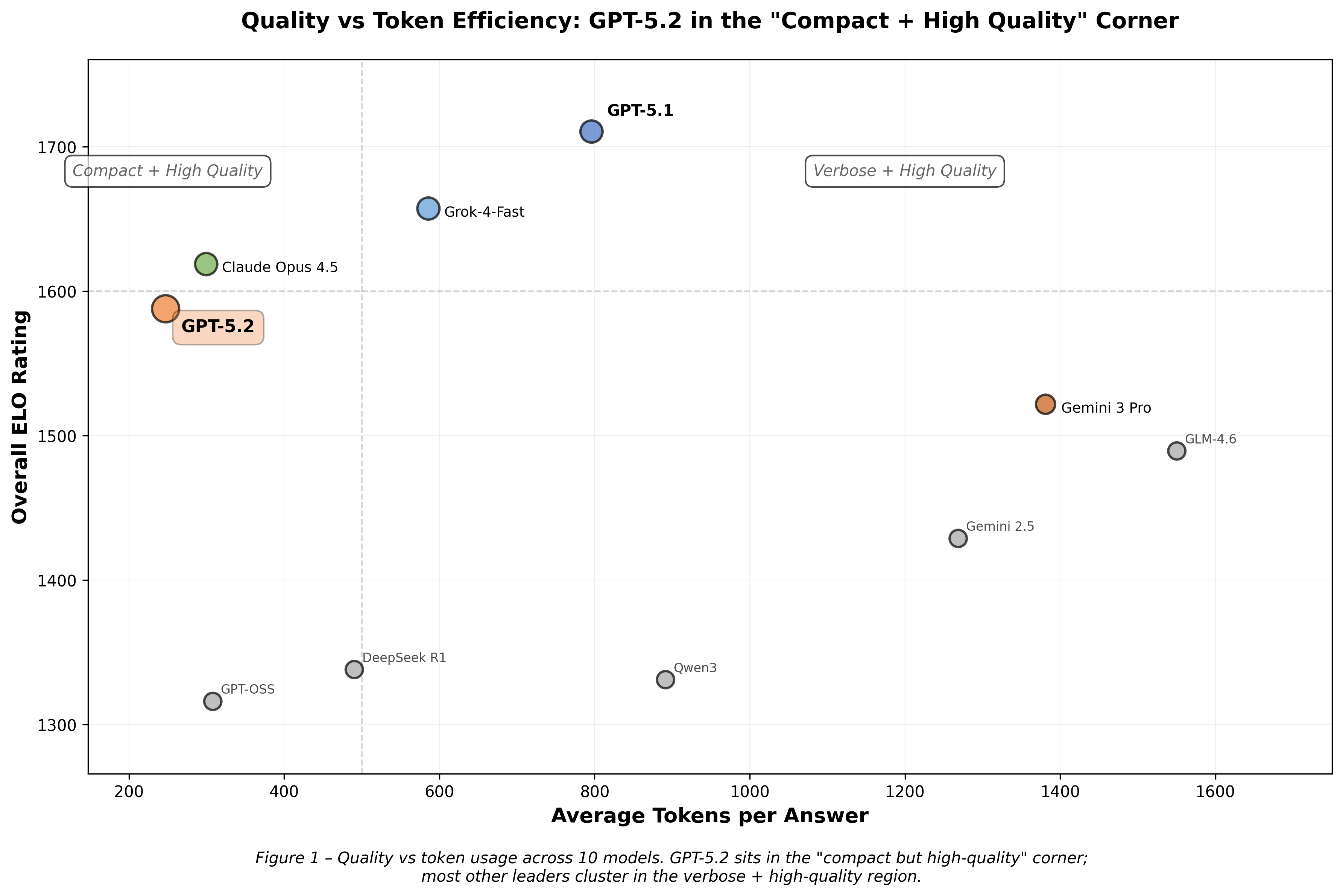
A few patterns stand out when you look at GPT-5.2 on the leaderboard:
- Overall position: GPT-5.2 sits in the top group, ranked #4 with 1588 ELO. GPT-5.1 is #1 at 1711 ELO.
- Token usage: GPT-5.2 uses roughly 3× fewer tokens per answer on average (247 vs 796 for GPT-5.1).
- Scientific reasoning: On our scientific claim verification tasks, GPT-5.2 is the top model, with 1605 ELO, about +17 ELO ahead of GPT-5.1 and ahead of every other model we tested.
- Stability across domains: GPT-5.2 is much more stable across the three RAG workloads, with a coefficient of variation of around 0.8% (compared to 7.3% for GPT-5.1).
1. Shorter Answers, Similar Quality


Across all three workloads, GPT-5.2’s answers are much shorter than GPT-5.1’s.
So roughly a 70% drop in token usage.
Even with that gap, the judge scores on correctness, faithfulness, and grounding usually stay close between the two models. On many questions, both are rated highly; GPT-5.2 just spends fewer tokens getting there. It removes restatements and side explanations and goes straight to: answer + key evidence.
For chat-style products, this difference is mostly about tone. For high-throughput or cost-sensitive RAG systems, cutting answer length by this much has a very direct impact on latency and API cost.
2. Where GPT-5.2 Leads: Scientific Claim Verification
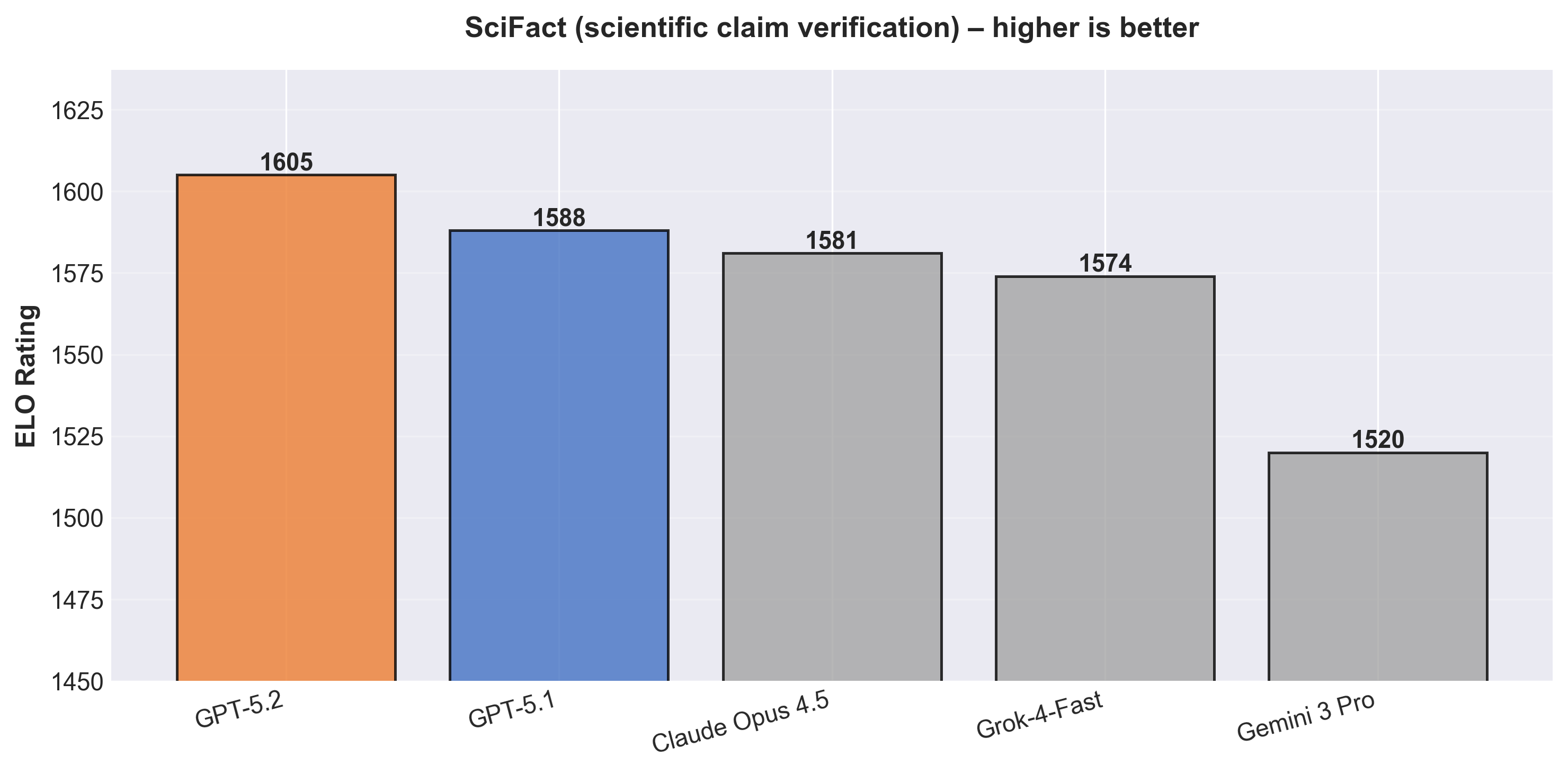
On scientific claim verification, GPT-5.2 is the best model we tested.
These queries look like:
Here is a claim and one or two evidence passages.
Is the claim supported, contradicted, or unclear?
Good answers are short and anchored to the text: a clear stance and a pointer to the exact sentence or result.
In this setting, GPT-5.2 reaches 1605 ELO, slightly ahead of GPT-5.1 and above every other model. In concrete examples, both often choose the same label and cite the same experiment. The difference is how they say it: GPT-5.1 adds more narrative and framing; GPT-5.2 keeps only what is needed to justify the decision.
For scientific and technical RAG—where users move through many such claims—this compact, evidence-first style is closer to what the task actually demands.
3. Consistency Across MSMARCO, PG Essays, and SciFact
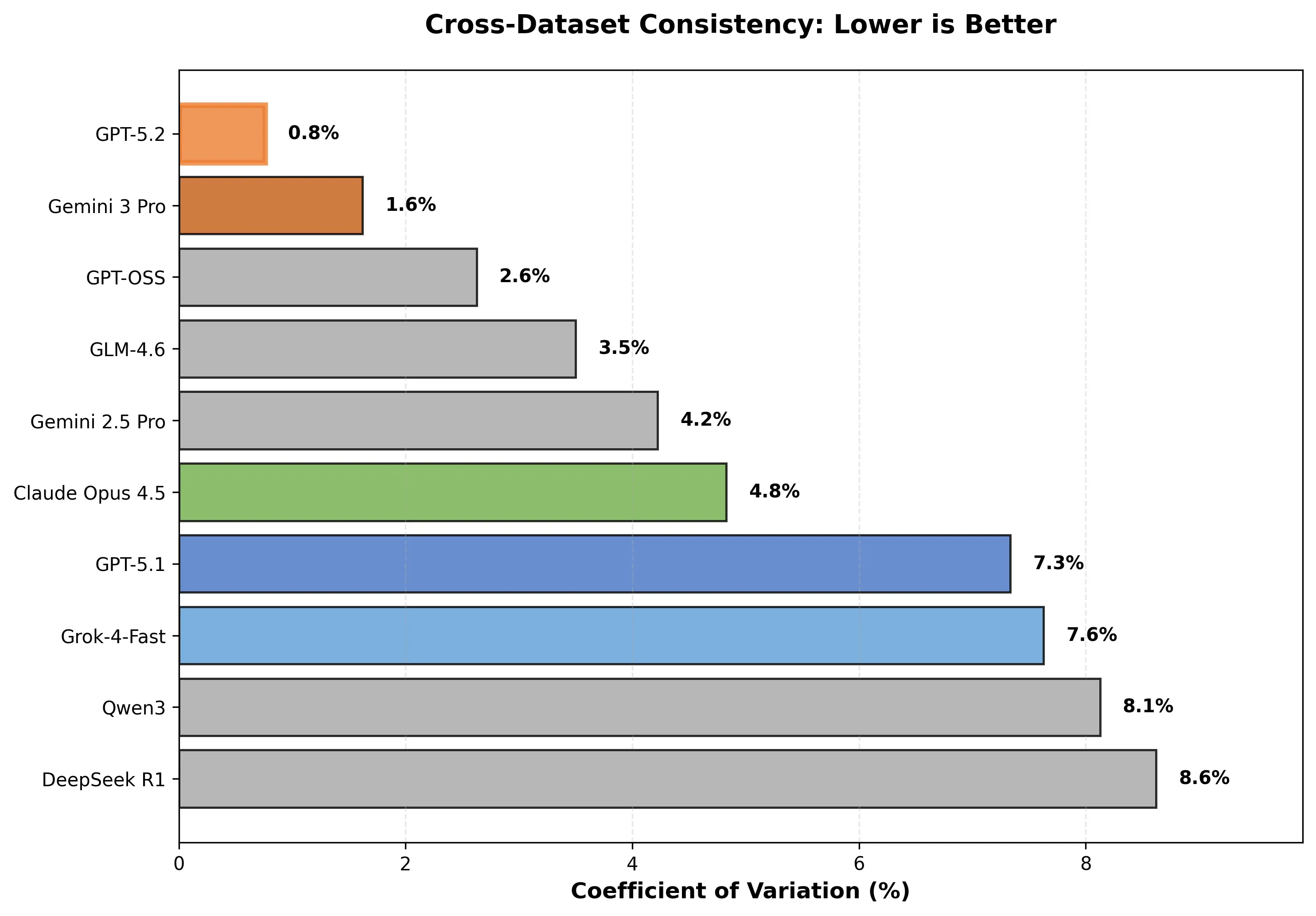
GPT-5.2 is also more stable across the different workloads.
If we look at its ELO scores per workload and compute the coefficient of variation:
GPT-5.2 stays close to its baseline level whether the query is a short factual question, a long reasoning prompt, or a scientific claim. GPT-5.1 (and some of the other leaders) hit slightly higher peaks in some areas, but move more between them.
Put together with the token findings, GPT-5.2 looks less like a “general assistant” and more like a compact specialist: high RAG quality, relatively uniform across workloads, and a much smaller token footprint per answer.
When is GPT-5.2 a Good Fit?
This benchmark suggests GPT-5.2 is a good match when:
- you are serving scientific or technical users who mainly care about the conclusion and the supporting evidence
- cost and latency are real constraints, so large cuts in token usage matter
- your RAG traffic mixes factual, reasoning, and scientific queries, and you want steady behaviour across them
- your product benefits more from concise, information-dense outputs than from long, conversational explanations
In those cases, GPT-5.2 behaves in line with the goal: it reads the retrieved documents, takes a clear stance, cites the key lines, and stops.
If you want to see how GPT-5.2 compares to GPT-5.1, Grok-4-Fast, Claude Opus 4.5, Gemini 3 Pro, GLM, and the strongest open-source models, the full breakdown is available on our LLM leaderboard.