

RAG helps a lot. But hallucinations still happen.
Even with correct context retrieved, the model can still say something unsupported or answer the wrong thing confidently. That's why hallucination detection ends up being a real production component.
So the real question isn't whether hallucinations exist - it's how you detect them without breaking latency, cost, or user experience.
TL;DR
LLM Judges are the most accurate, Atomic Claim Verification is thorough but slow, and encoder-based NLI provides a strong production trade-off. The catch is that NLI evaluates factual support, not relevance, which can still lead to bad answers in user-facing systems.
Four Common Approaches: Our Test Results
1. LLM Judge
Utilizes specialized LLM prompts to analyze generated text for factual inconsistencies or unsubstantiated claims.
Achieved a 100% success rate across all metrics (Accuracy, Precision, and Recall). While highly effective, it comes with a latency and cost trade-off because it adds an extra LLM call.
2. Atomic Claim Verification
Breaking the response into individual sentences and verifying each one independently against the source using llm, for preventing a minor hallucination in a large accurate response.
Achieved 72.7% accuracy with perfect 100% recall, successfully catching every hallucination in the test set. However, it struggled with precision (66.7%), meaning it sometimes over-flagged correct statements as hallucinations.
Most notably, it was the slowest method by far, with an average latency of 10,774ms roughly 8× slower than the LLM Judge and 22× slower than the NLI classifier.
3. Encoder-based models
This approach uses models like BERT to analyze the deep semantic relationship between texts. Unlike LLMs, encoders are specialized for comparing a response to its source to check whether the claim is supported.
We tested this using LettuceDetect to identify and flag unsupported claims.
Demonstrated strong performance with 90.9% Accuracy and a 92.3% F1 Score. It achieved 100% recall (missed no hallucinations), with one false positive (a correct statement flagged as hallucinated).
Overall, this represents a highly efficient and cost-effective alternative to full LLM-based verification.

4- Fine-tuned LLM detectors
Employs models like Llama-2 or Llama-3 specifically trained on datasets of factual and hallucinated text. This specialization allows them to recognize subtle error patterns and domain-specific fabrications more effectively than general-purpose models.
While potentially a very strong detector, it requires significant GPU clusters and high operational costs for training and maintenance. We have earmarked this for future evaluation to see if the performance gains justify the overhead.
The Performance vs. Cost Trade-off
If you need production-scale speed without sacrificing much accuracy, the NLI Classifier is a strong option delivering ~91% accuracy at a fraction of the cost of an LLM Judge.
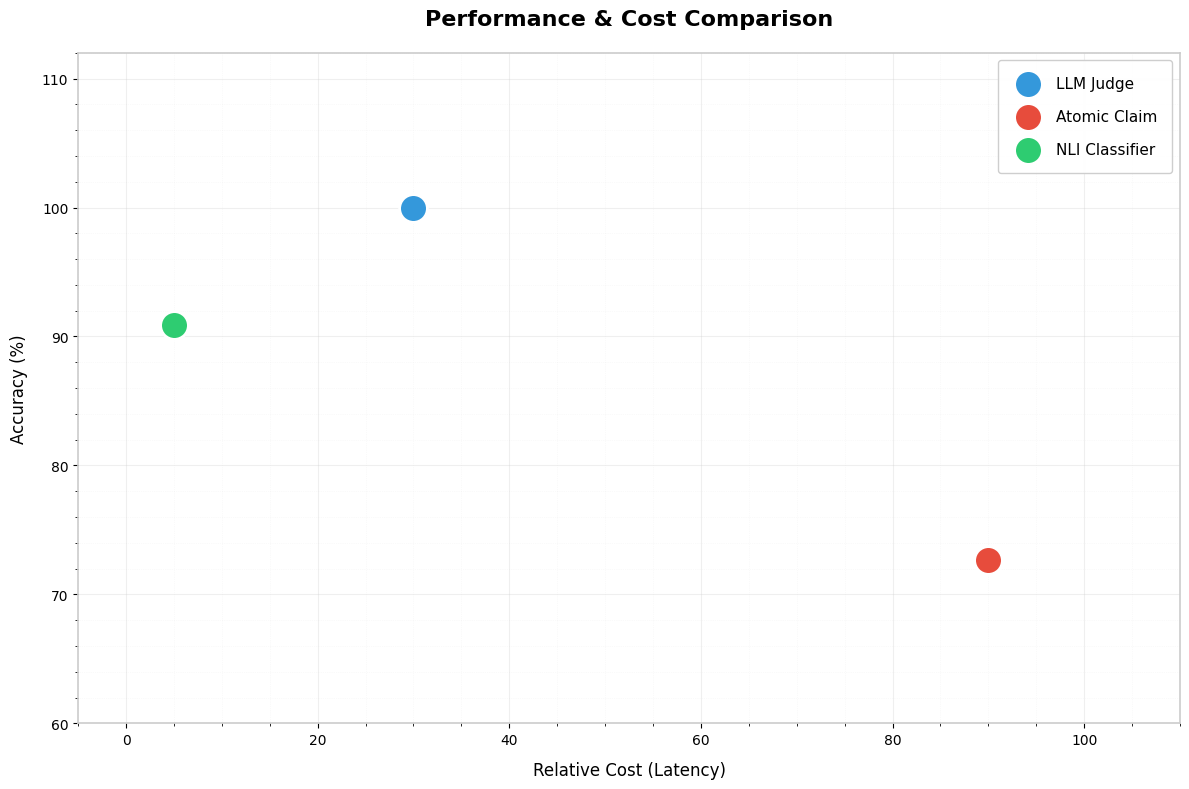
While the LLM Judge is the gold standard for accuracy, its added latency can become a bottleneck at scale. Conversely, Atomic Claim Verification provides sentence-level checking but is too slow for real-time applications.
Selecting the Right Approach for Your Pipeline
Choosing a detection method is a balancing act between accuracy, operational cost, and the end-user experience. Here is how we recommend deploying these strategies:
-
High-Fidelity Validation (LLM Judge): This approach is best suited for high-stakes applications like legal, medical, or financial reporting where accuracy is non-negotiable. In our testing, it achieved a 100% success rate across all metrics. However, it comes with an added latency cost (averaging ~1,300ms per call) and relies on premium API usage.
-
Real-Time Production (Encoder-based / LettuceDetect): This is a practical choice for high-volume, user-facing applications. It maintained a strong 90.9% accuracy while delivering a sub-second latency of 486ms. It also runs on CPU, making it easier to scale without GPU clusters.
However, during evaluation we observed that encoder-based NLI classifiers can struggle with symbolic and numeric precision. For example, a generated response may correctly reference the source but alter a single digit in a date (e.g., "2023-05-17" instead of "2023-05-15"). Despite this discrepancy, the model may still classify the claim as supported due to the preserved semantic structure.
-
Sentence-Level Precision (Atomic Claim Verification): This approach is designed to catch subtle hallucinations that often hide within long, mostly accurate responses by verifying each sentence independently. While it achieves 100% recall, the granular verification is computationally heavy, resulting in an average latency of 10,774ms (22 times slower than encoder-based models). Because it tends to over-flag factual statements, it is best reserved for workflows where catching every possible detail is more critical than real-time speed.
-
Domain-Specific Specialization (Fine-tuned Detectors): This strategy is a long-term play for organizations with unique data patterns or niche jargon. While highly capable, it requires a significant upfront investment in training data and specialized infrastructure. We view this as an advanced stage for teams looking to optimize once a baseline system is already in place.
The "Blind Spot": Factuality vs. Relevance
While the chart makes a strong case for the NLI Classifier especially considering it can run efficiently on a CPU with minimal latency our testing revealed a critical nuance that numbers alone don't show.
The NLI (Natural Language Inference) model is a specialist in entailment. It asks one specific question: "Is this claim supported by the provided context?" During our evaluation, we noticed an interesting pattern:
If the LLM provides a response that is completely irrelevant to the user's question, but every word of that response is factually supported by the source documents, the NLI Classifier flags it as 100% successful.
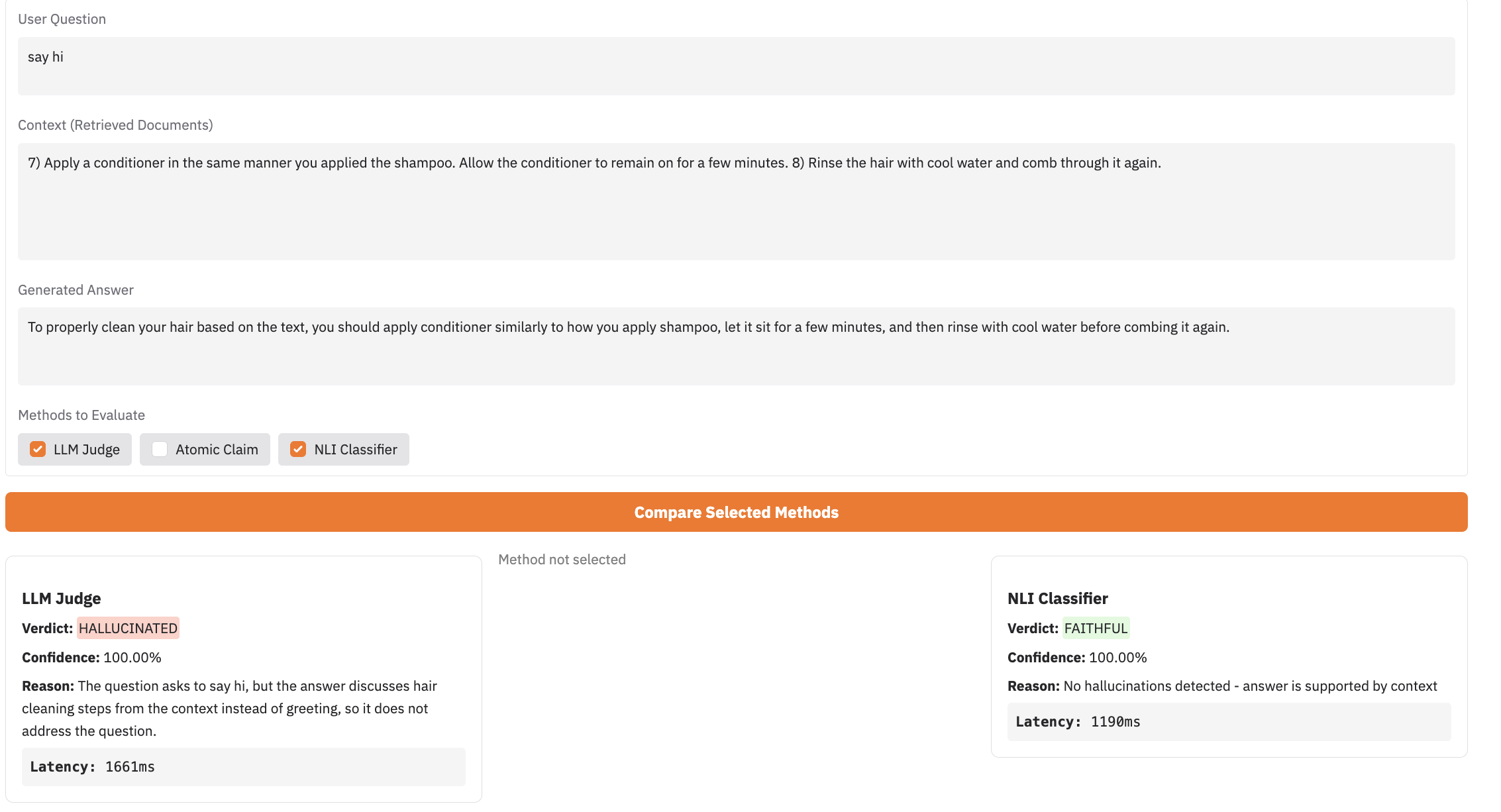
Testing Methodology & Setup
- The Dataset: We used RAGTruth but manually modified samples with subtle hallucinations and altered text to create "tricky" test cases that push each detector to its limit.
- The Hardware: LLM-based evaluations were executed in the cloud using GPT-5, while encoder-based experiments were run locally on a MacBook Air M1 using CPU-only.
Conclusion
RAG reduces hallucinations, but it does not eliminate them. Even with the right context, models can still produce confident but unsupported claims.
The key takeaway is that there is no single best detector. Each approach trades off accuracy, latency, and cost, and the right choice depends on how critical correctness is for your system. In practice, reliable RAG pipelines treat hallucination detection as a first-class component, not an optional add-on.
References
[1] RAGTruth: A Dataset for Hallucination Detection in Retrieval-Augmented Generation
[2] LettuceDetect: A Hallucination Detection Framework for RAG Applications