

Opus 4.5 dropped yesterday, so we wanted to see how it behaves inside a real RAG pipeline, not just on benchmark charts. Benchmarks are nice, but RAG doesn’t care about benchmarks — it cares about behavior under noisy retrieval.
In RAG, the model has to work with large, imperfect contexts, decide which pieces of retrieved text actually matter, and then produce a concise, grounded answer instead of rewriting everything it sees. That makes RAG evaluation fundamentally different from standard LLM tests.
To understand how Opus behaves under these constraints, we reran the exact same setup from our previous experiment (Gemini 3 Pro vs GPT 5.1): same retrieval, same context, same evaluation flow — only the model changed.
In that earlier test, we saw clear stylistic differences:
- Gemini stayed close to the retrieved text and avoided drifting
- GPT 5.1 was more expressive but often pulled in extra details
Now the question is: Where does Opus fit between these behaviors?
Below are five behavior questions that matter in real RAG systems, and how Opus compares.
Question 1: Does it keep the answer tight, or does it ramble?
The “how to boil eggs” test exposes verbosity quickly.
As in the previous experiment:
- Gemini dumped almost the entire chunk
- GPT 5.1 stayed minimal

Opus sits between them:
- It follows the main boiling method cleanly
- It avoids Gemini-level text dumping
- But it still adds extra details (sous-vide, “it’s worth noting…”, comments about egg freshness)
- The tone is more narrative than GPT’s step list
TL;DR: Opus is controlled but not concise. It wants to be helpful by adding context, even when the question didn’t ask for it.
Question 2: What happens when it doesn’t know the answer?

When a question that has no supporting evidence in the dataset is asked, Gemini and GPT both refused — but over-cited unrelated people/topics from the chunks.
Opus shows the same pattern:
- It refuses properly
- but still adds unnecessary citations and restates irrelevant chunk context
The “Who is Elon Musk?” test highlights the same issue:
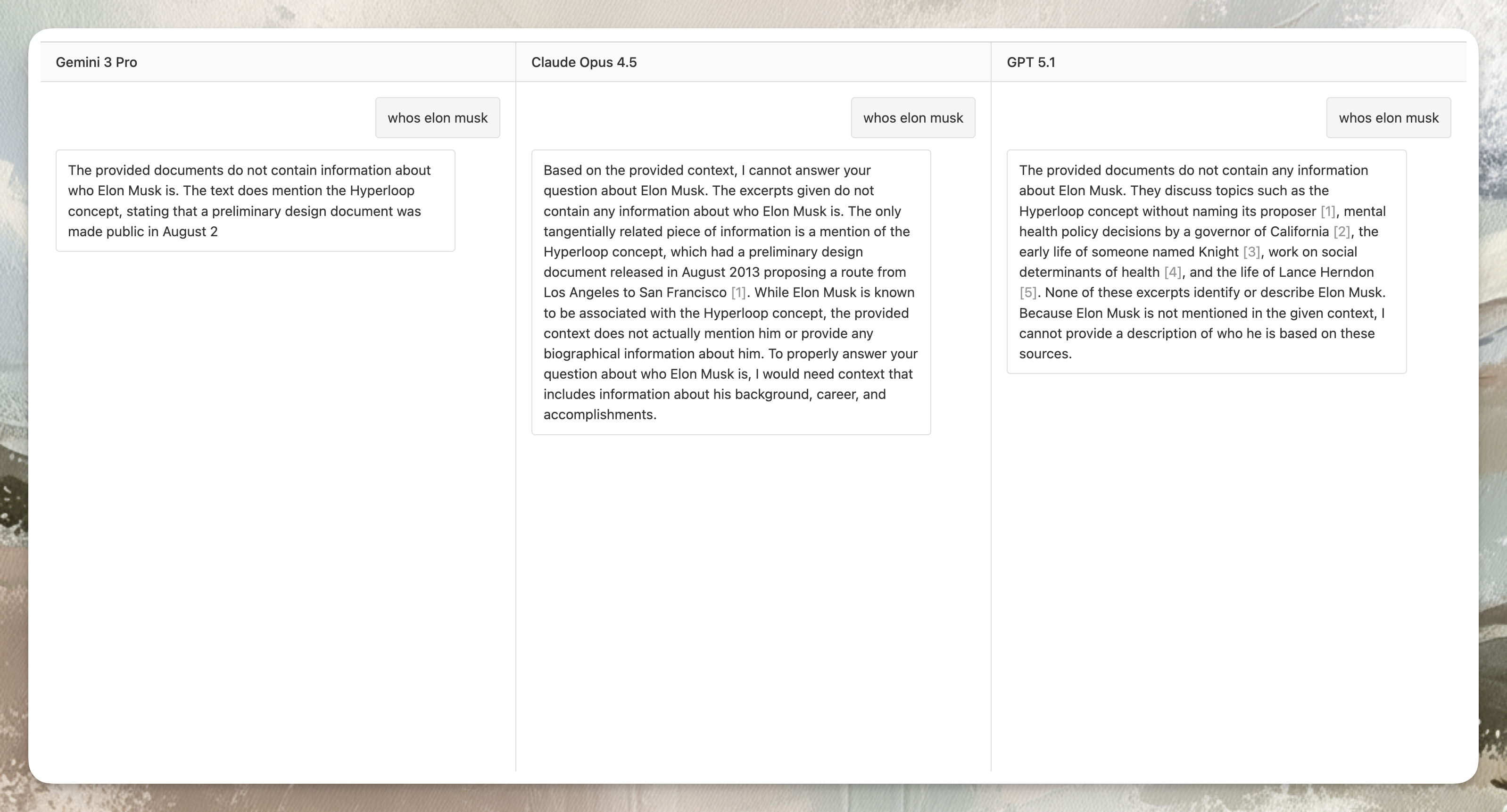
Even though the dataset never links Musk to Hyperloop, all three models bring Hyperloop into the answer — meaning they rely on their own prior knowledge, not the retrieved text.
TL;DR: For grounding safety, there isn’t a huge behavioral gap. All three models are still too “explanatory” in their refusals.
Question 3: Does it stay on-topic, or does it drift?
Relevance issues show up when the chunk contains multiple topics.
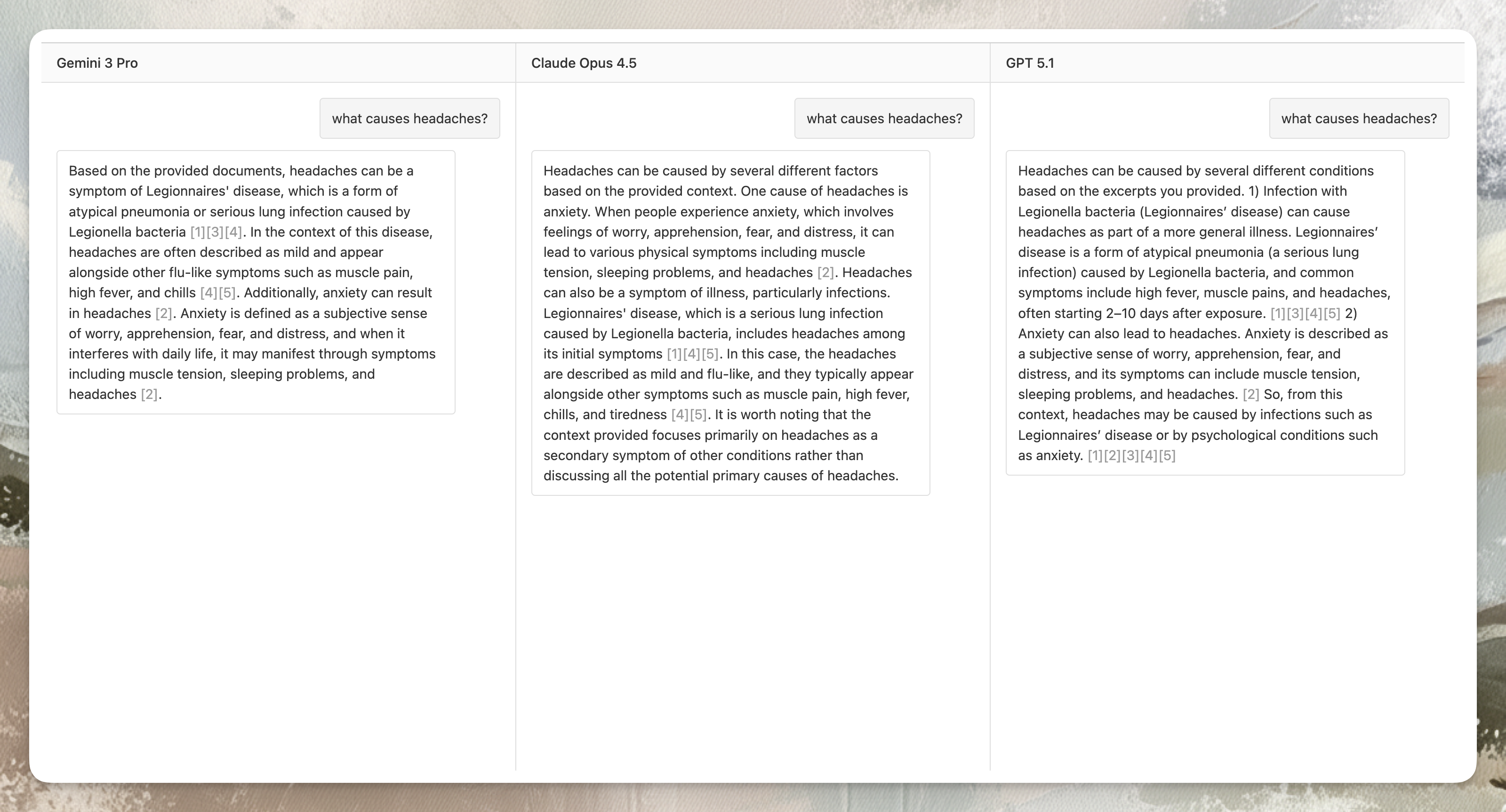
All three models stay mostly on-topic here, but:
- Gemini tends to mix symptoms from different parts of the chunk
- GPT lists everything
- Opus explains the same facts but organizes them more coherently
TL;DR: As a relevance filter, Opus is slightly stricter and more readable, but not fundamentally different from GPT.
Question 4: Can it explain processes cleanly, or does it add noise?
This is the first category where Opus clearly diverges.

The photosynthesis question is a good reasoning test.
- GPT 5.1 includes every possible detail, even borderline irrelevant ones
- Gemini stays shorter but sometimes under-explains
- Opus walks a clean middle line: fully reasoned, structured, readable, no unnecessary tangents
Here you actually see the “Opus 4.5 reasoning improvement” show up inside RAG.
TL;DR: Opus feels like the model that understands the shape of a process and can retell it cleanly.
Question 5: Does it actually use the retrieved text, or does it make things up?
The “what temperature does water boil at?” question highlights this nicely:

- All three models get 212 °F correct because it’s in the source
- Gemini and Opus both include extra info about vacuum boiling
- GPT 5.1 chooses not to
Opus also adds:
“the boiling process itself is when a substance changes…”
which is technically correct, but not required by the question.
TL;DR: Opus uses all the relevant text but also adds contextual framing when it isn’t strictly needed. Good for readability, less ideal for strict extraction.
So, how does Opus 4.5 behave overall?
Across all five behaviors, the pattern is consistent:
- More structured than Gemini — avoids uncontrolled text-dumping
- Clearer and more coherent than GPT 5.1 — explanations are cleaner and easier to follow
- Behaviorally similar to GPT on grounding and relevance — still adds small side-notes
- Strongest category: reasoning clarity — cleanest multi-step explanations
Taken together, these behaviors show that Opus 4.5 is currently the strongest overall model for RAG.
It keeps the answer structured, stays coherent even when the context is messy, and reasons through the text without drifting.
From a RAG-pipeline perspective — where large contexts, selective extraction, and concise grounded answers matter — Opus 4.5 offers the most balanced and reliable behavior among the three models evaluated.