
 Anthropic released Claude Opus 4.6 yesterday. We evaluated it in a RAG setup to understand how it performs across factual retrieval, synthesis, and scientific tasks.
Anthropic released Claude Opus 4.6 yesterday. We evaluated it in a RAG setup to understand how it performs across factual retrieval, synthesis, and scientific tasks.
Method: 90 queries total (30 per task type). Each model gets the same top-15 retrieved documents, then we run pairwise comparisons against 11 frontier models. ELO is computed from win/loss/tie outcomes (judge: GPT-5).
Overall
- Strong on factual QA: ~81% win rate
- Clear upgrade over Opus 4.5: large gains on synthesis-heavy tasks (~+387 ELO)
- More concise than GPT-5.1: consistent on simpler tasks, less depth on long-form reasoning
The main tradeoff is precision versus depth.
Factual Retrieval
Opus 4.6's strongest results appear on straightforward factual queries. It achieves an 81.2% win rate (268–16–46), the highest score in this category in our run.
A key factor here is how the model handles uncertainty. When an answer is not clearly supported by the retrieved documents, it tends to stop rather than extend beyond the context. This behavior aligns well with production RAG systems where grounding matters more than verbosity.
Improvement over Opus 4.5
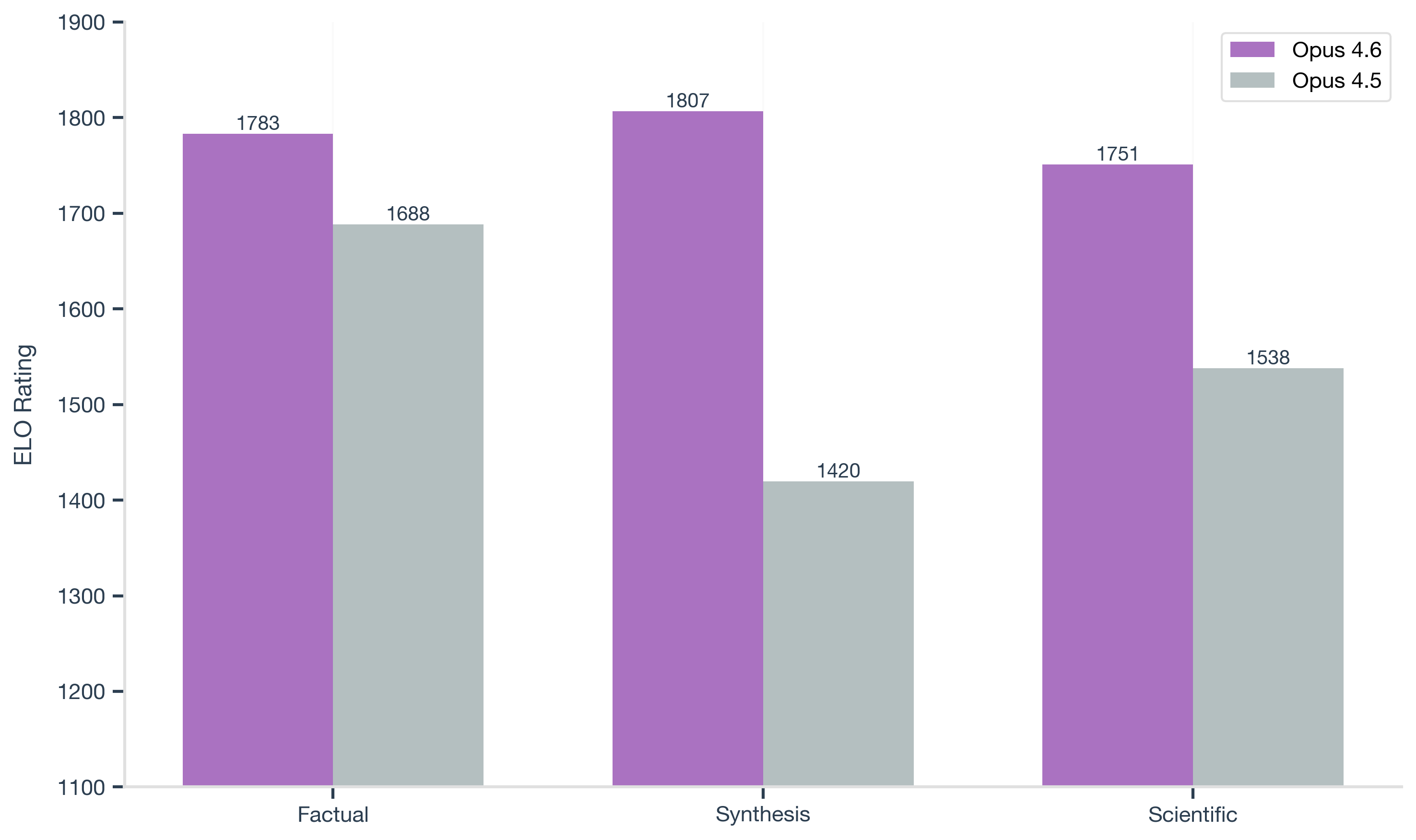
Compared to Opus 4.5, Opus 4.6 performs better across all task types. The largest improvement appears in synthesis (+387 ELO), indicating substantially stronger handling of long-context reasoning in this version.
This change is especially visible on multi-document queries, where 4.5 often degraded as context length increased.
Head-to-head with GPT-5.1
Although Opus 4.6 ranks higher overall (1780 vs. 1716 ELO), it underperforms GPT-5.1 in direct synthesis comparisons.
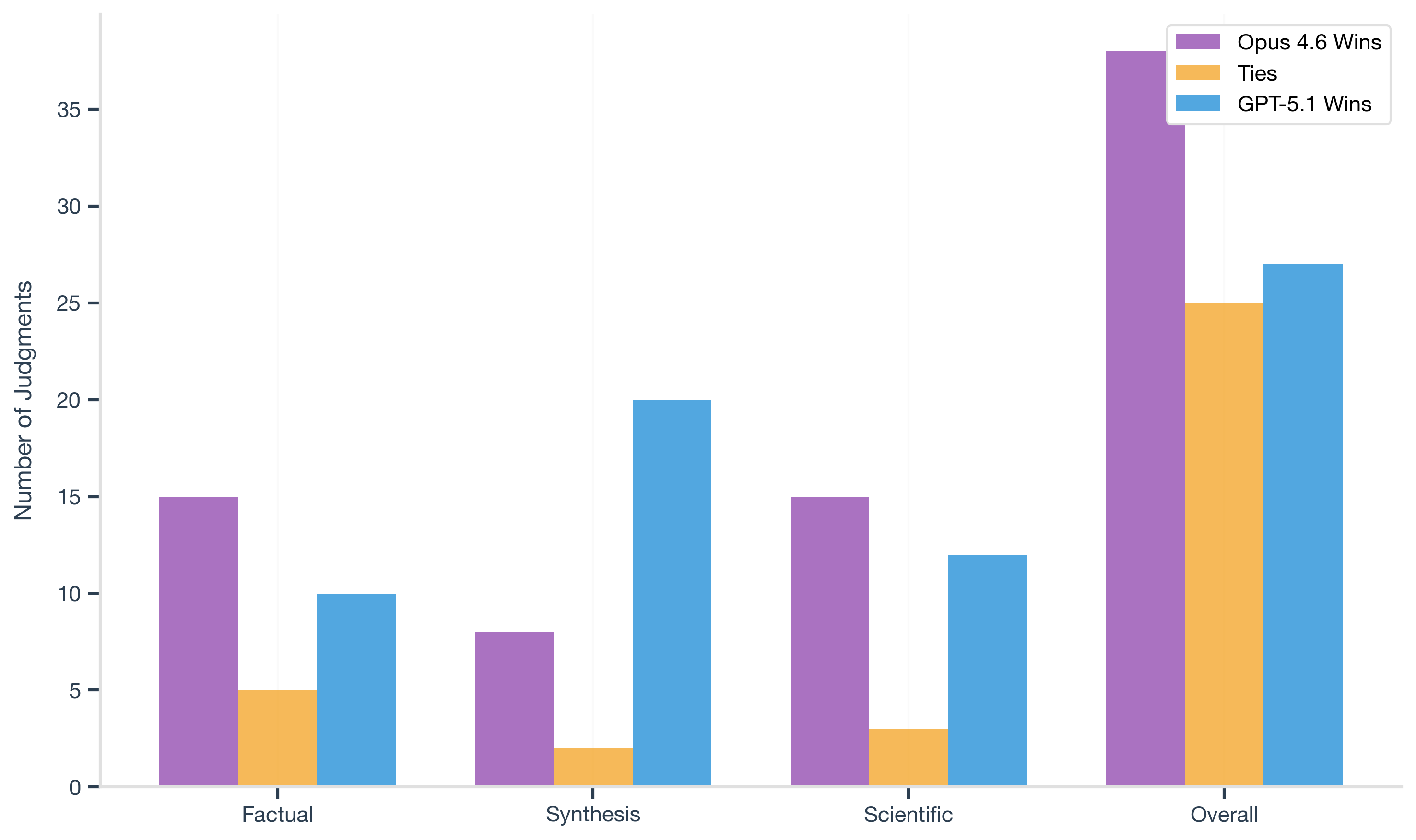
On synthesis tasks, GPT-5.1 outperforms Opus 4.6 (20–8–2) in head-to-head matchups. Opus 4.6 is more consistent across the full model set, while GPT-5.1 performs better on complex, long-form reasoning tasks. This explains how Opus 4.6 can rank higher overall while still losing on synthesis-heavy workloads.
Latency behavior
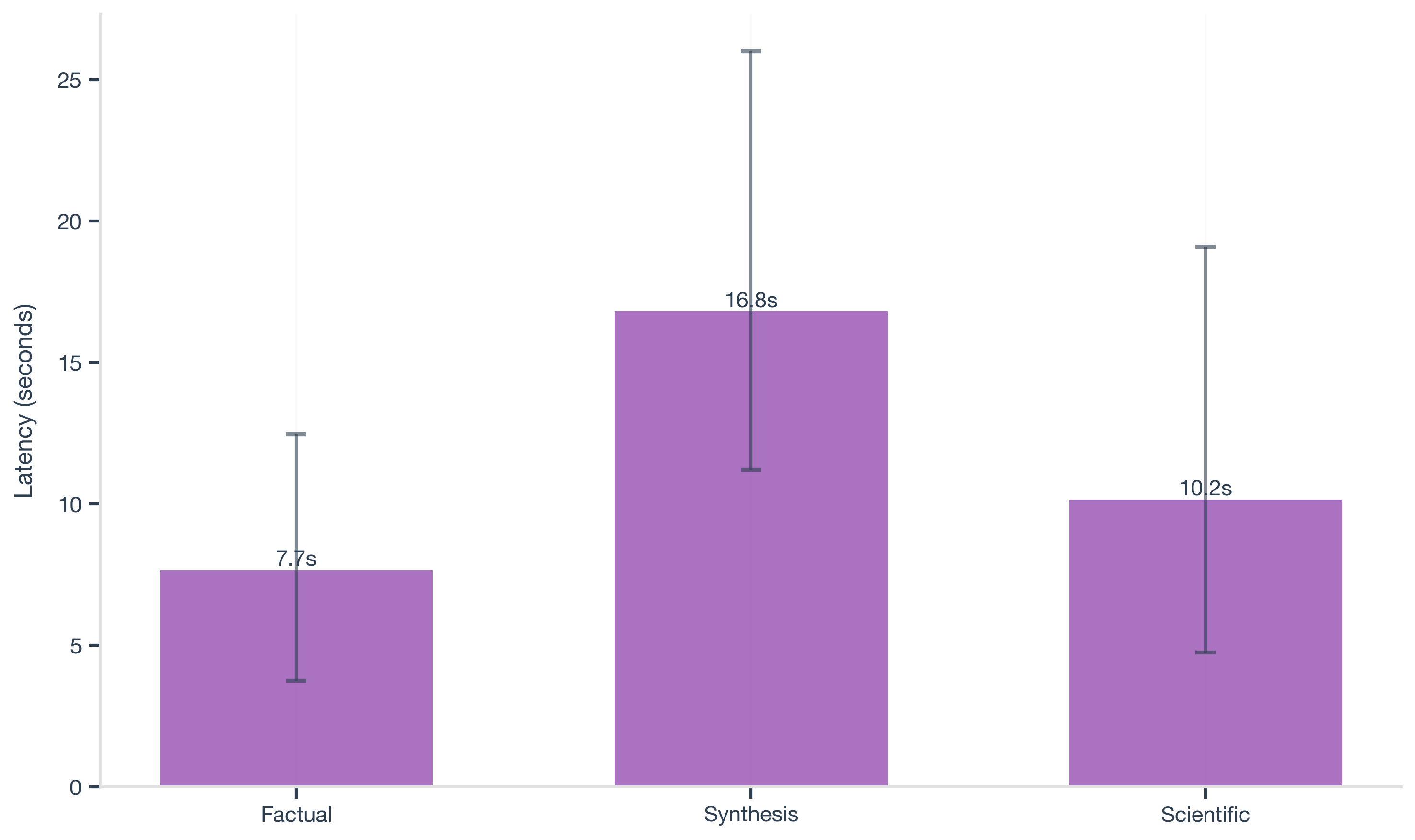
Latency varies with task complexity:
- Factual: 7.7s average
- Synthesis: 16.8s average
- Scientific: 10.2s average
Synthesis is consistently slower. This aligns with the model doing more work on harder queries, instead of treating every question the same.
Final Note
Claude Opus 4.6 is a strong precision-first RAG model. It represents a clear step forward from Opus 4.5 and performs especially well on retrieval-heavy workloads where factual accuracy and grounding matter more than verbosity.
We recommend Opus 4.6 as a default choice for factual QA and source-critical RAG systems. For workloads that rely heavily on long-form synthesis or explanatory depth, GPT-5.1 remains the better option.
We've added Opus 4.6 to the Agentset LLM leaderboard for direct comparison against GPT-5.x, Gemini, Grok, and others across task types.