

Anthropic released Claude Sonnet 4.6, and we added it to our LLM-for-RAG leaderboard to test three workloads:
- Factual QA (web-style passages)
- Long-form synthesis (essay / narrative content)
- Scientific verification (claims grounded in papers)
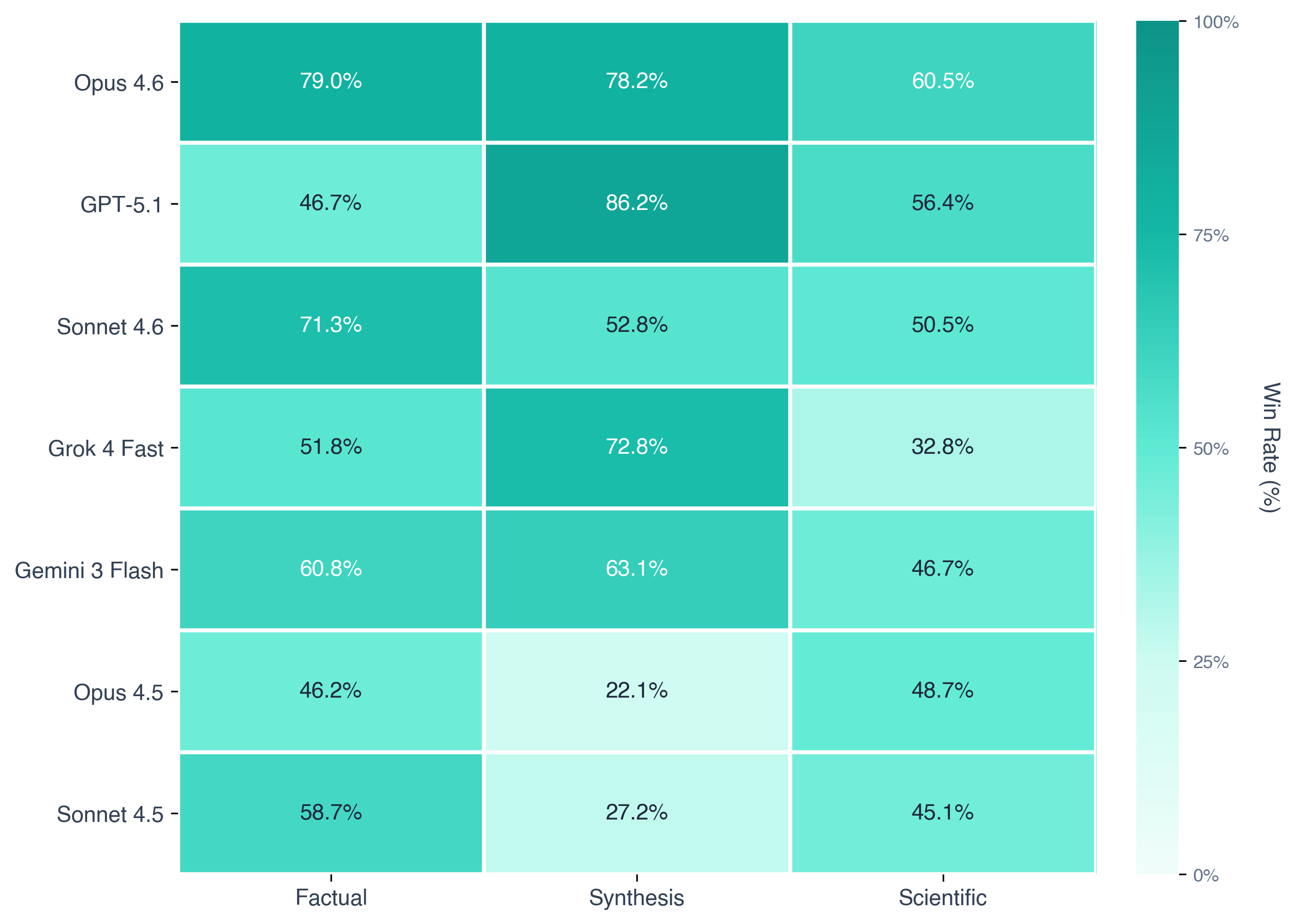
TL;DR: Sonnet 4.6 placed #3 overall, behind Opus 4.6 and GPT-5.1. Biggest win was long-form synthesis. Smallest edge is on scientific verification.
Key Findings
Factual answers
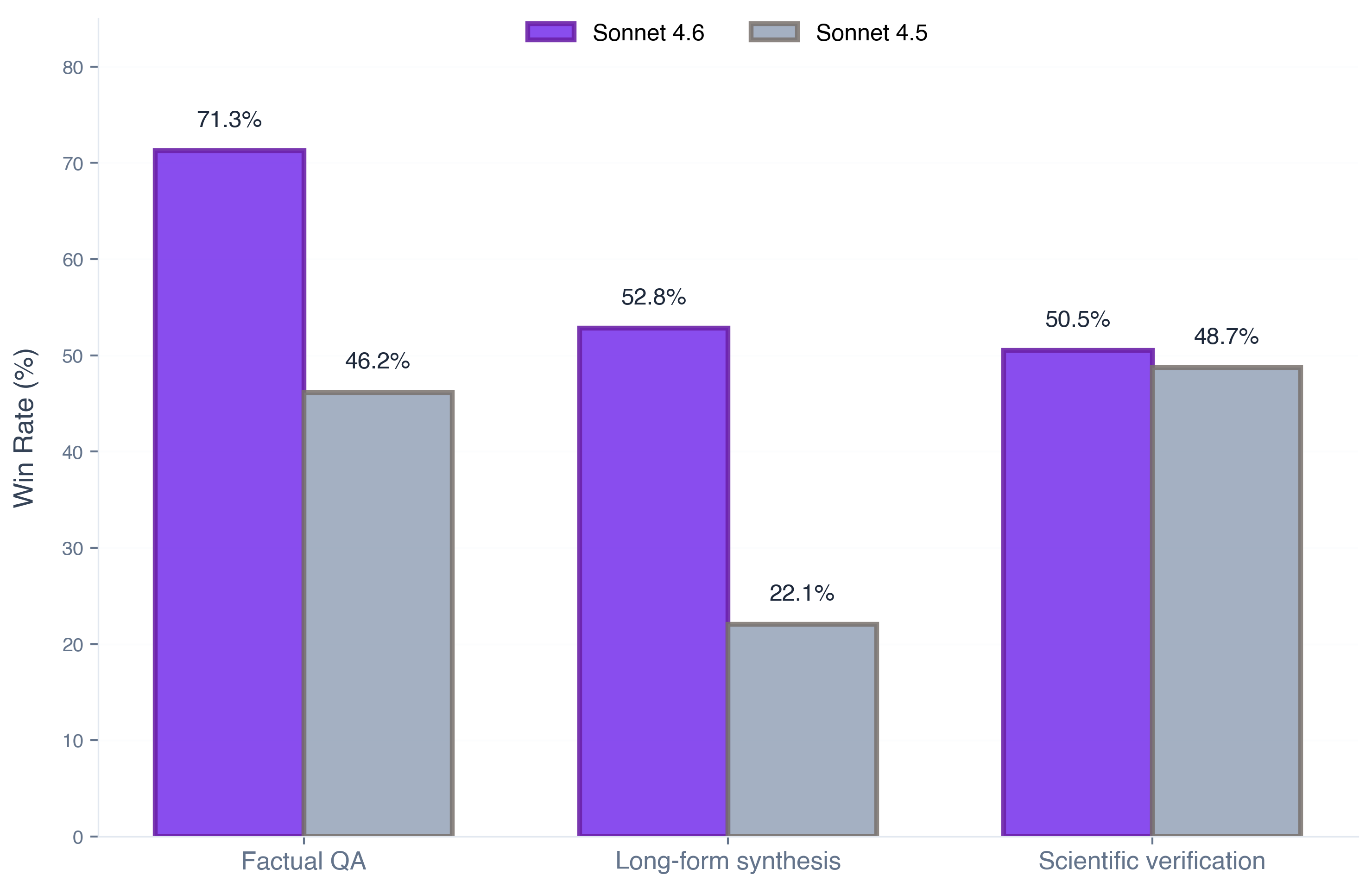
Sonnet 4.6 was strong on factual QA. It generally pulled the answer directly from retrieved passages and avoided unnecessary filler.
It ranked #2 with a 71% win rate, well ahead of Sonnet 4.5 at 59%. In practice, this shows up as cleaner, more grounded answers.
Synthesis: biggest improvement
This is where Sonnet 4.6 separates from 4.5.
On long-form synthesis, Sonnet 4.6 wins nearly 2x more often than 4.5 (53% vs 27%). This is the largest gap across all three workloads.
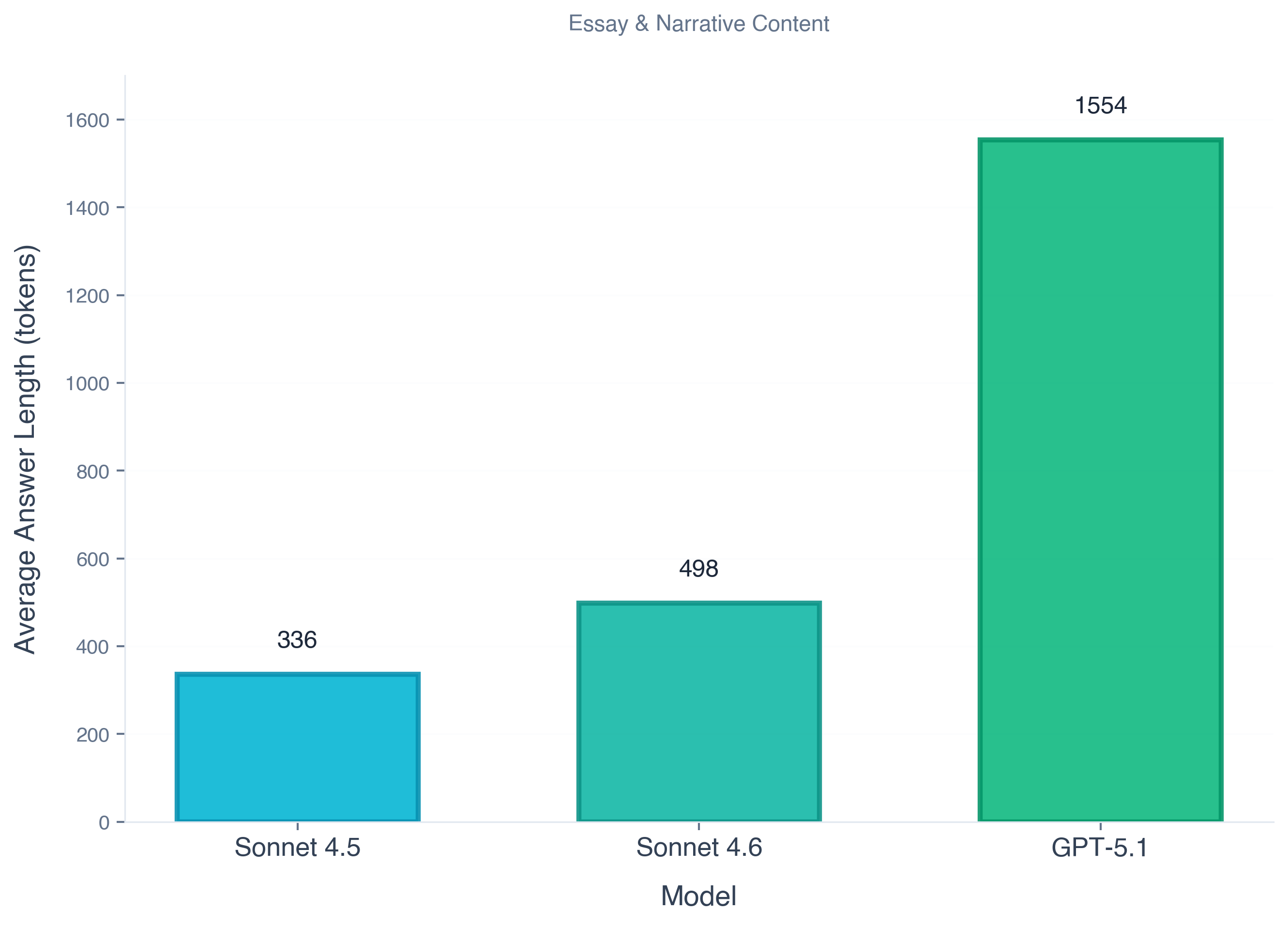
The extra quality comes with extra depth. Sonnet 4.6 averaged 498 tokens per answer vs 336 for Sonnet 4.5 (+48%).
In practice, 4.6 connects ideas across chunks instead of just listing what each source says.
Scientific claims: smallest gap
Sonnet 4.6 still leads on scientific tasks, but it's narrow:
Sonnet 4.6 edges out 4.5 by just 5 points (50% vs 45% win rate) - the smallest margin across all workloads.
The pattern fits: 4.5's literal, conservative style is more competitive on strict verification, while 4.6's explanatory depth has less advantage here.
Takeaway
Sonnet 4.6 is a strong general-purpose RAG model (#3 overall). Its biggest gain is long-form synthesis, where it nearly doubles 4.5's win rate.
For best overall quality, use Opus 4.6 or GPT-5.1 (top 2 on the leaderboard). If your workload is mostly factual Q&A and synthesis and you want a lighter option, Sonnet 4.6 is the better pick. For scientific verification, 4.6 and 4.5 are close: 4.6 explains more, 4.5 is shorter and more literal.
See the full rankings and per-task breakdown on the LLM-for-RAG leaderboard.