
Voyage AI recently released Voyage 4. We spent some time running it through our evaluation pipeline to see how it shifts the needle for RAG compared to Voyage 3 Large and current frontier embedding models.
Here is what we found.
The Evaluation
We tested 14 models across 6 datasets, covering financial Q&A, web search, scientific claims, and entity retrieval. We used two primary lenses:
- Traditional metrics: NDCG@10.
- LLM-as-a-judge: Pairwise comparisons aggregated into ELO ratings. We had GPT-5 compare the Top-5 results from model pairs to determine which set provided better context for the query.
Key Observations
Voyage 4 is currently the strongest general-purpose model we've tested.
- Win Rate: 61.7% across 780 head-to-head comparisons.
- Elo: 1606 (the highest in our current pool).
- Precision: 0.859 NDCG@10.
The most interesting signal is the Top-K density. Voyage 4's advantage over its predecessors grows by 2.3× when you evaluate only the Top-5 results instead of the Top-10. It's significantly more "top-heavy" with relevant information.
Domain Performance: Factual vs. Reasoning
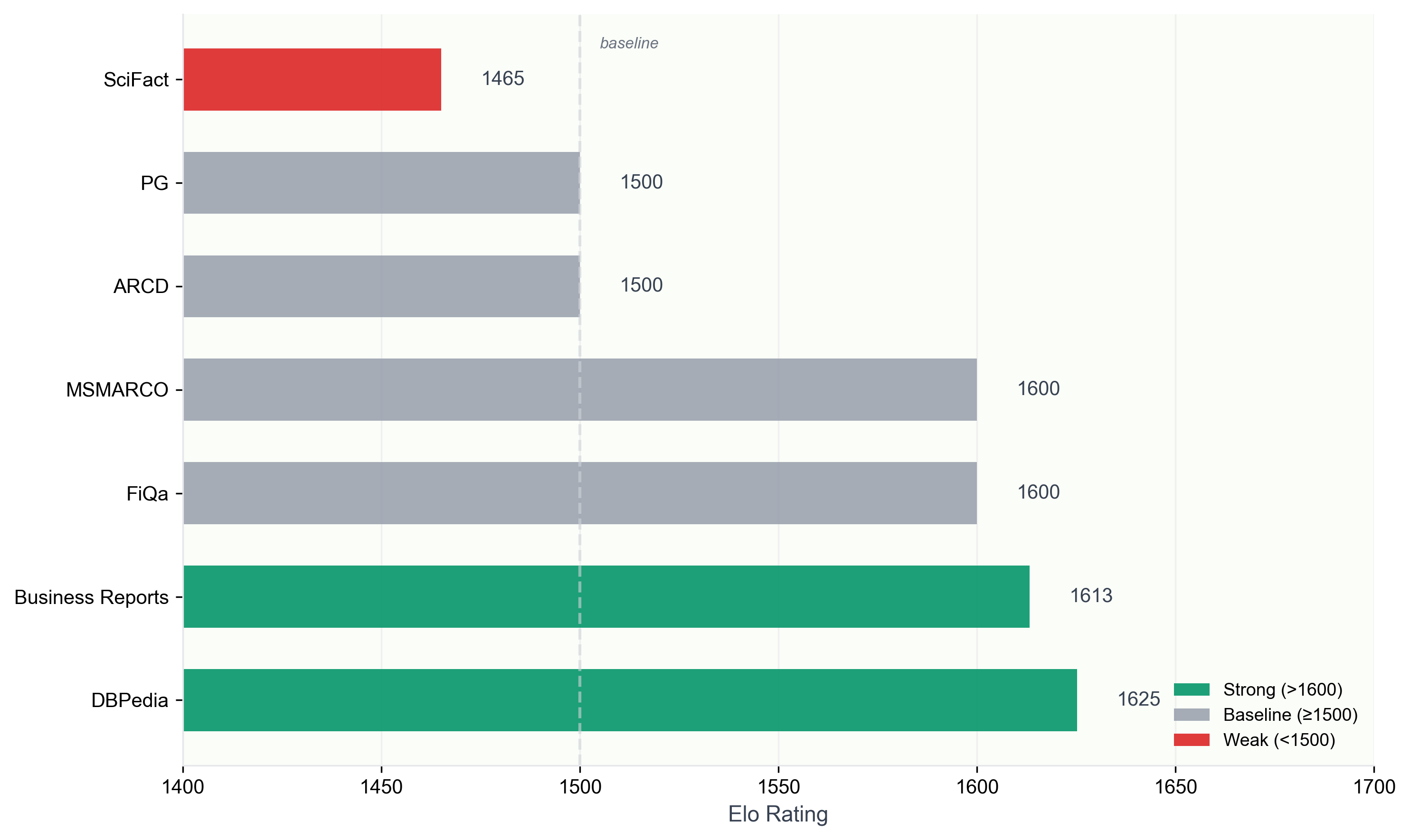
The model isn't a linear upgrade across every domain. It has a very specific signature.
- Entity-Rich & Business Documents: The model is strongest here. It performed exceptionally well on DBPedia and Business Reports, making it ideal for finding specific data points in professional documents.
- The SciFact Ceiling: This was the only outlier. Voyage 4 dropped to 1465 Elo with a 90% tie rate. It seems to hit a wall on tasks requiring subtle scientific reasoning or evidence-contradiction analysis. It behaved like a high-end semantic matcher, but not a "reasoner."
The OpenAI Parity
We found a perfect stalemate between Voyage 4 and OpenAI text-embedding-3-large.
- Record: 28 wins – 28 losses – 4 ties. Neither model could establish dominance over the other across 60 queries. They currently sit in an elite tier together, roughly 60+ Elo points above the rest of the field.
Retrieval Quality in RAG
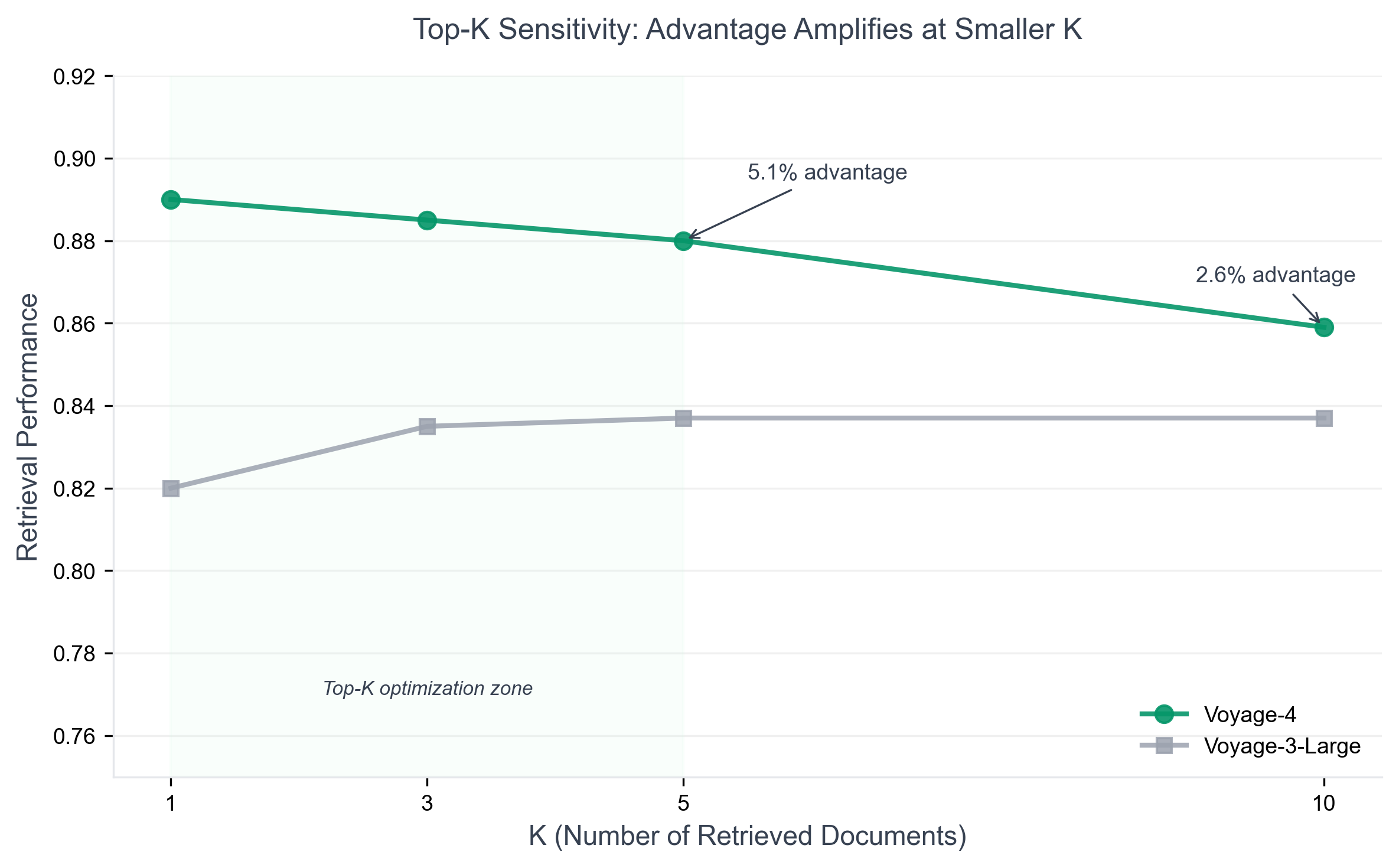
Most RAG systems are optimized for Top-3 or Top-5 chunks to reduce noise and context costs. This is where Voyage 4 makes the most sense.
We looked at a specific query regarding post-2000 gold economics:
- Voyage 4: Returned 5/5 chunks directly addressing gold price drivers (QE3, real interest rates, financial crisis).
- Voyage 3 Large: Returned 0/5 relevant chunks. It surfaced "finance-adjacent" noise - Hyundai cruise control pricing and IRS tax procedures.
The semantic overlap in Voyage 3 Large was too broad. Voyage 4 surfaced answerable context where the predecessor only found topical keywords.
Conclusion
Voyage 4 is currently the strongest general-purpose model on our leaderboard. If your RAG system relies on factual retrieval and you are optimizing for a small context window (Top-5), this should be the new default.
Full dataset breakdowns and rankings are at the embeddings leaderboard.