
 ZeroEntropy just released zembed-1. It's a 4 billion parameter embedding model distilled from their zerank-2 reranker. We ran it through our evaluation suite to see how it performs on real retrieval tasks.
ZeroEntropy just released zembed-1. It's a 4 billion parameter embedding model distilled from their zerank-2 reranker. We ran it through our evaluation suite to see how it performs on real retrieval tasks.
TL;DR
zembed-1 is now the highest-ranked model on our leaderboard, edging out Voyage 4, OpenAI text-embedding-3-large, and Jina Embeddings v5 Text Small in pairwise comparisons. Strongest on general document retrieval and multilingual tasks. Weaker on scientific and entity-heavy tasks.
What We Found
Best passage retrieval score
On MSMARCO - the standard information retrieval benchmark and the closest proxy to real RAG workloads - zembed-1 hit 0.946 NDCG@10. That's the highest score across all 16 models in our
leaderboard.
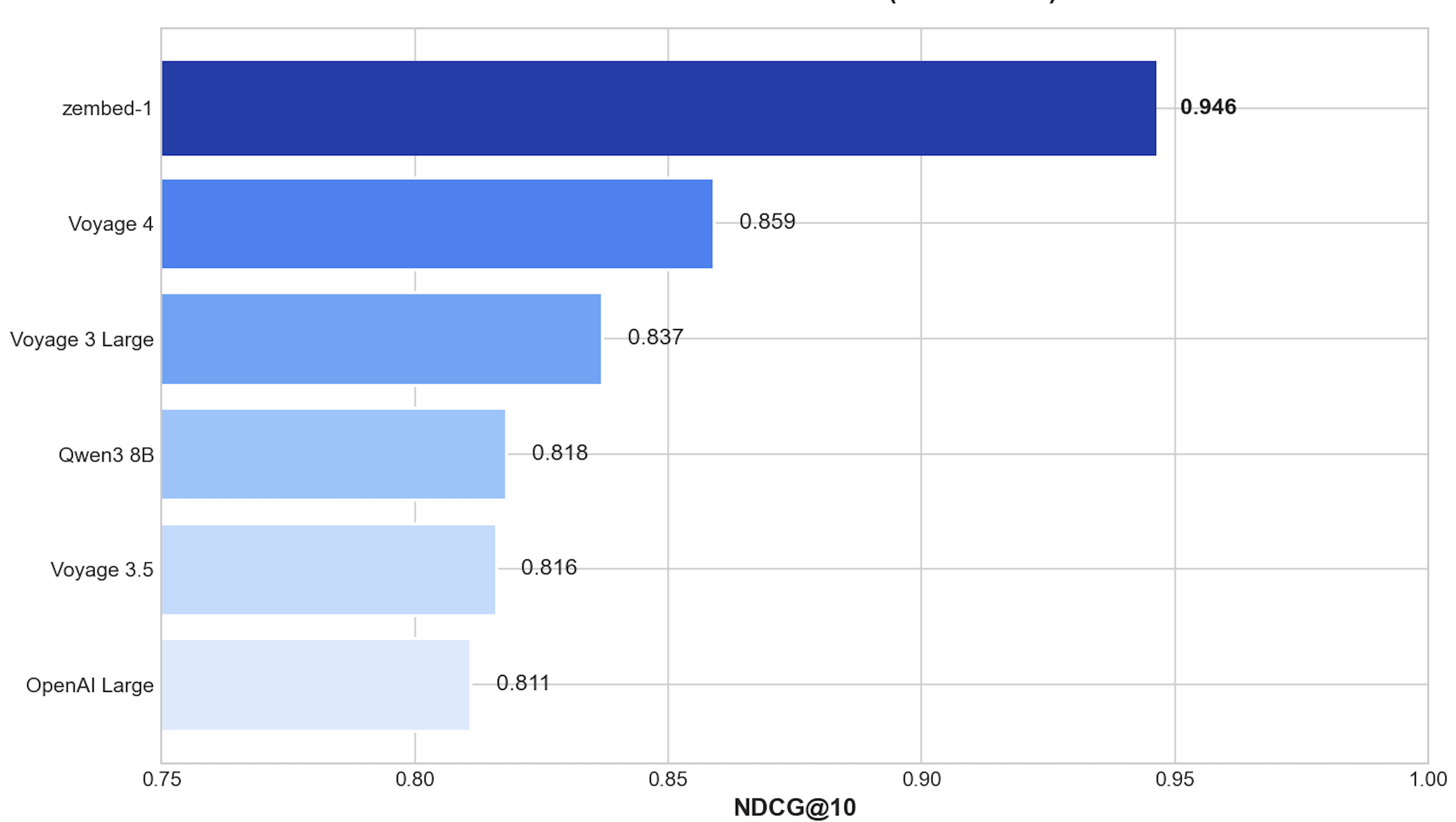 MSMARCO tests short queries against large document collections. A 0.946 means zembed-1 consistently puts the right documents at the top.
MSMARCO tests short queries against large document collections. A 0.946 means zembed-1 consistently puts the right documents at the top.
Wins most head-to-head matchups
We ran pairwise comparisons across all 15 other models. zembed-1 wins 55-80% of matchups against most of the field. Against Gemini text-embedding-004, it wins 80%. Against Jina Embeddings v3 and Cohere Embed v3, around 67%.
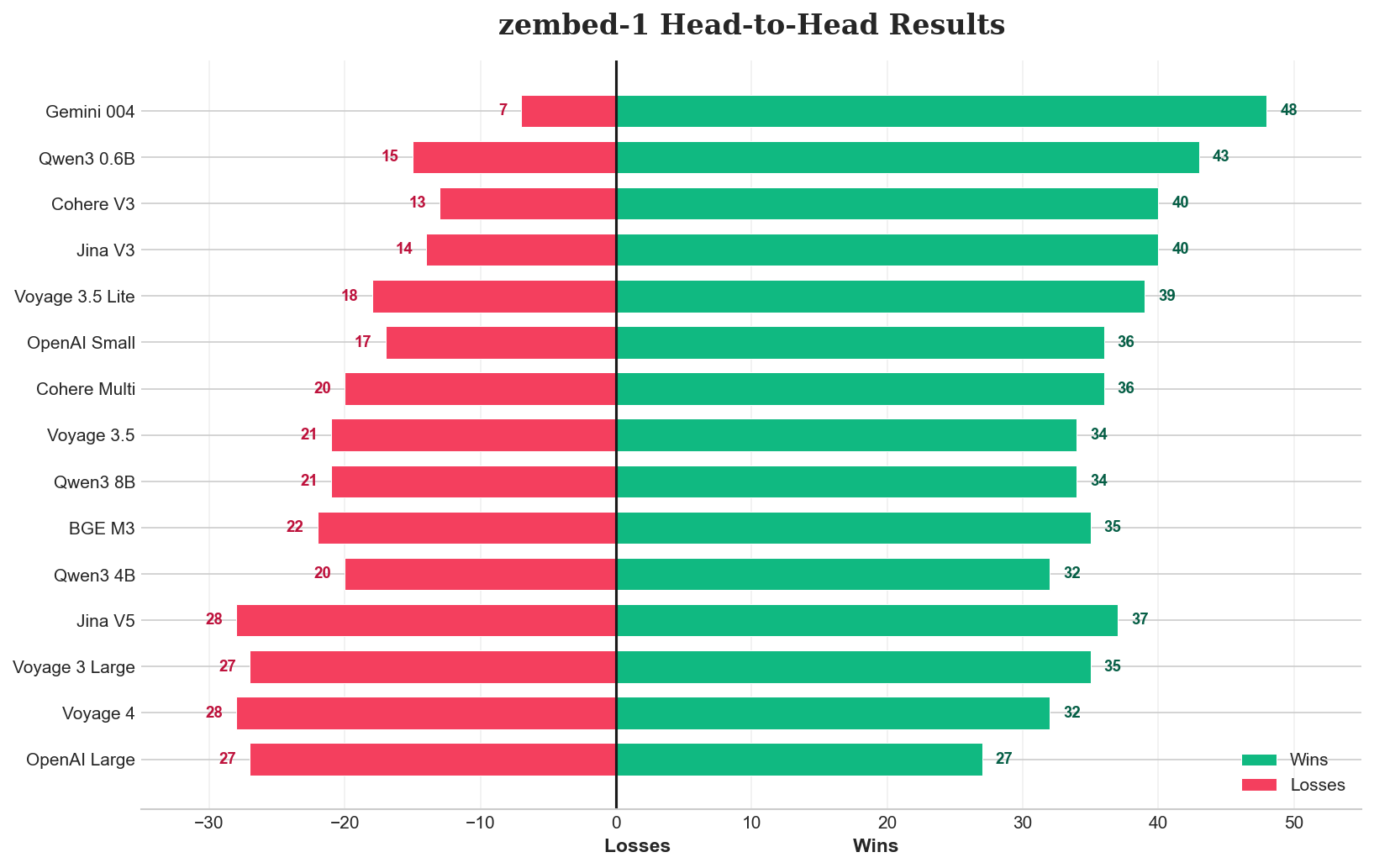 The exceptions are the top 3: Voyage 4, OpenAI text-embedding-3-large, and Jina Embeddings v5 Text Small. Against these, zembed-1 is essentially even - win rates hover around 45-53%. No clear winner, which puts zembed-1 in the same competitive tier as models that have been around longer.
The exceptions are the top 3: Voyage 4, OpenAI text-embedding-3-large, and Jina Embeddings v5 Text Small. Against these, zembed-1 is essentially even - win rates hover around 45-53%. No clear winner, which puts zembed-1 in the same competitive tier as models that have been around longer.
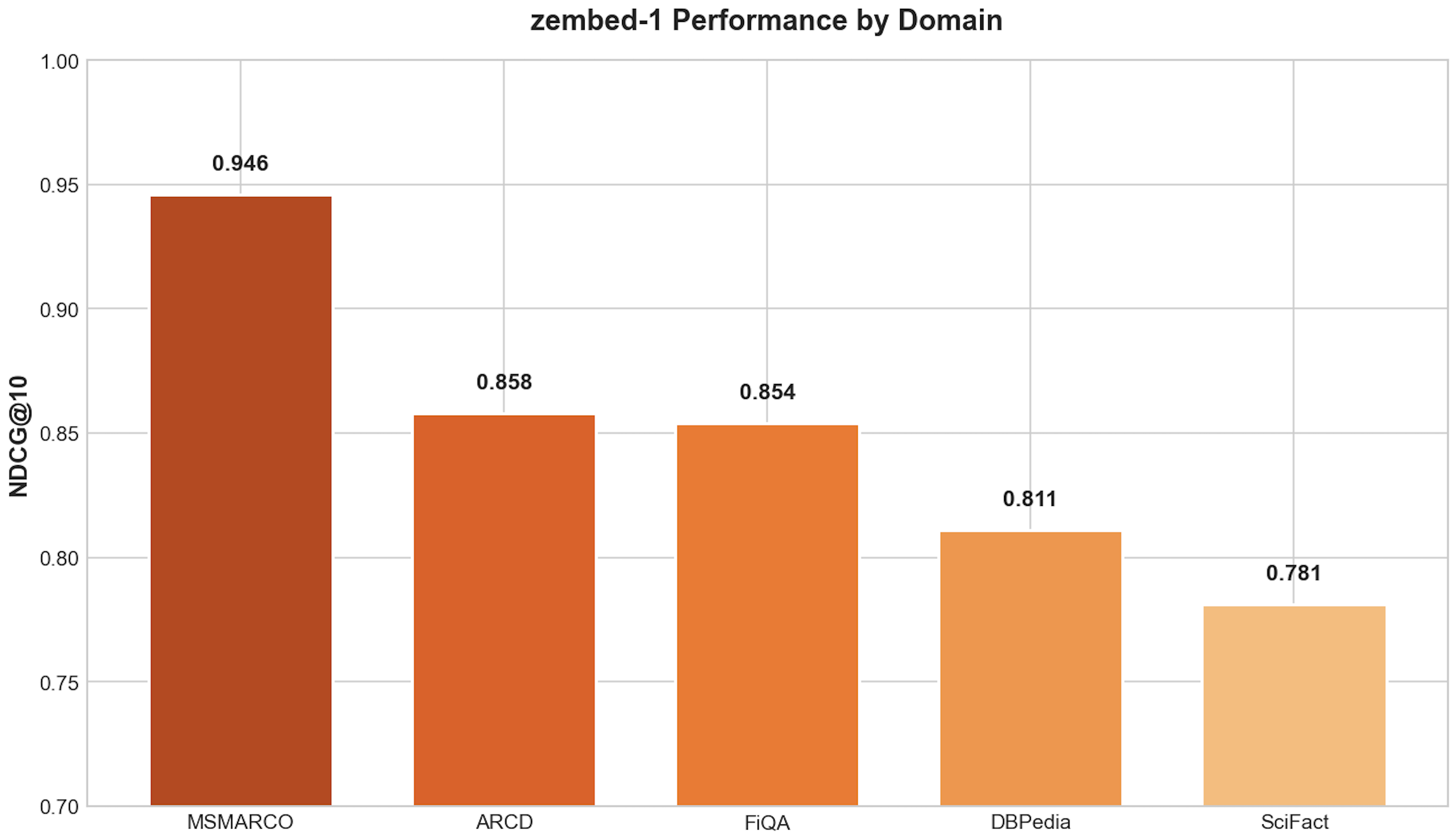
Performance varies by domain
zembed-1 is not uniformly strong. Broken out by dataset:
The gap between general retrieval and scientific content is real. If your corpus is mostly research papers or knowledge-graph-style entity lookups, the top-tier models on those specific workloads still outperform zembed-1 by a meaningful margin.
How We Tested
- Each model embedded the same corpus and queries
- Retrieved top-10 results per query, calculated NDCG@10 and Recall@10
- Elo ratings from pairwise comparisons using GPT-5 as judge
- 5 datasets with human-annotated relevance: MSMARCO (general-purpose), FiQA (finance), SciFact (science), DBPedia (entities), ARCD (Arabic) + two private datasets
Conclusion
zembed-1 is the strongest embedding model we've tested on general-purpose retrieval, and it competes with the top tier across most general workloads. For RAG pipelines that handle unstructured documents, business content, or multilingual queries, it's worth testing.
We've added zembed-1 to our Embedding Leaderboard where you can compare it against Voyage 4, OpenAI text-embedding-3-large, Cohere Embed v3, and others across all datasets.